DMflow.chat
廣告
DMflow.chat:智慧整合,創新溝通!除了持久記憶與客製欄位外,更支持真人與 AI 的靈活轉換,無縫連接資料庫與表單,讓網頁互動更靈活高效。
探索由騰訊音樂 Lyra Lab 開發的 MuseTalk 技術。了解這款開源 AI 模型如何實現即時、高品質的影片唇形同步,支援多種語言,並了解其最新 1.5 版本的技術革新與應用潛力。
你有沒有想過,讓影片中的人物嘴型完美配合任何語音,而且效果自然、反應即時?過去這可能是個耗時費力的過程,但現在,AI 技術正在改變這一切。今天我們就要來聊聊一個由騰訊音樂娛樂集團(TME)旗下的 Lyra Lab 推出的厲害工具——MuseTalk。
簡單來說,MuseTalk 是一款專注於即時、高品質唇形同步(Lip-Syncing)的 AI 模型。想像一下,只需要輸入一段音訊,它就能讓影片中的人物臉部、特別是嘴唇,跟著音訊內容「動起來」,而且效果非常逼真。更厲害的是,它的處理速度快到可以在 NVIDIA Tesla V100 這樣的 GPU 上達到每秒 30 幀以上,這意味著什麼?意味著即時處理的可能性!
而且,MuseTalk 不僅僅是個實驗室裡的玩具。它已經在 GitHub 上開源,模型也可以在 Hugging Face 找到。這對開發者和創作者來說,無疑是個好消息。
MuseTalk 的核心能力是根據輸入的音訊,去修改一個它從未見過的臉孔(unseen face)。它會專注在一個 256 x 256 像素大小的臉部區域進行修改,確保嘴型、下巴等部位的動作與聲音同步。
它有幾個特別值得注意的亮點:
MuseTalk 的運作方式相當聰明。它並不是直接在原始圖像上操作,而是在一個叫做「潛在空間」(Latent Space)的地方工作。你可以想像成,它先把圖像壓縮成一種「精華」表示,然後在這個壓縮的空間裡進行修改,最後再還原成圖像。
主要技術組成部分:
ft-mse-vae)來將圖像轉換到潛在空間。Whisper-tiny 模型(同樣是預訓練且固定的)來提取音訊中的特徵。Whisper 的強大之處在於它對多種語言的理解能力。一個重要的區別: 雖然 MuseTalk 用了類似 Stable Diffusion 的 UNet,但它並不是一個擴散模型(Diffusion Model)。擴散模型通常需要多個步驟來去噪生成圖像,而 MuseTalk 更像是在潛在空間裡做「單一步驟的圖像修補(inpainting)」,這也是它能實現即時推論的關鍵原因之一。
聽起來有點複雜,對吧?簡單來說,就是把聲音的「指令」和圖像的「畫布」(壓縮版的)結合起來,然後用一個強大的「畫筆」(生成網路)畫出對應的嘴型。
科技總是在進步,MuseTalk 也不例外。開發團隊在 2025 年初推出了 MuseTalk 1.5 版本,帶來了顯著的改進。這次升級主要做了幾件事:
這些改進讓 MuseTalk 1.5 在清晰度、身份保持(生成的臉看起來還是同一個人)以及唇語同步的精確性上,都比早期版本有了長足的進步。而且,更棒的是,1.5 版本的推論程式碼、訓練程式碼和模型權重現在都已經完全開放了! 這意味著社群可以基於這個更強大的版本進行開發和研究。
MuseTalk 這樣的技術能做什麼呢?用途其實非常廣泛:
如果你對 MuseTalk 感興趣,想親自動手試試,可以從以下幾個地方開始:
README 文件中的硬體和軟體依賴需求。由於 MuseTalk 已經開源了訓練程式碼,有能力的開發者甚至可以利用自己的資料集來微調或重新訓練模型,以滿足特定的需求。
我們整理了一些大家可能關心的問題:
MuseTalk 無疑是 AI 驅動內容創作領域的一個重要進展。它不僅展示了騰訊音樂 Lyra Lab 在音訊和視覺 AI 方面的技術實力,更透過開源的方式,將這種強大的能力帶給了廣大的開發者和創作者社群。
從即時虛擬人互動到高效的影視配音,MuseTalk 的出現打開了許多可能性的大門。隨著技術的持續演進和社群的共同努力,我們可以期待未來看到更多基於 MuseTalk 的創新應用。如果你對 AI 影片生成、虛擬人或只是想讓你的照片「唱首歌」感興趣,MuseTalk 絕對值得你關注和嘗試!
DMflow.chat:智慧整合,創新溝通!除了持久記憶與客製欄位外,更支持真人與 AI 的靈活轉換,無縫連接資料庫與表單,讓網頁互動更靈活高效。
Google Veo 2 登陸 AI Studio!免費試玩,人人都能變身 AI 導演? Google 最新的 AI 影片生成模型 Veo 2 終於在 AI Studio 開放免費試用了...
挑戰 Sora?Luojian 科技開源 Open-Sora 2.0 視訊生成模型 — 更便宜、更快、更強! 開頭 — Sora 太貴?Open-Sora 2.0 來了! 你知道嗎?OpenA...

BEN2:精準影像前景分割的 AI 解決方案 在影像處理領域,如何快速且準確地去除背景,一直是業界關注的重點。傳統方法依賴綠幕技術或手動摳圖,耗時且成本高昂。如今,BEN2 (Backg...

探索 FaceFusion 的奇幻世界 - 換臉AI 本次介紹將深入探討人臉融合技術 (FaceFusion) 的原理、應用及未來發展趨勢。我們將從人臉檢測、特徵提取到圖像融合等技術層面...

TransPixar:Adobe 最新突破性透明影片生成技術 前言 在影片生成技術快速發展的今日,Adobe 推出了革命性的 TransPixar 技術,這項創新不僅能透過文字和圖像生...
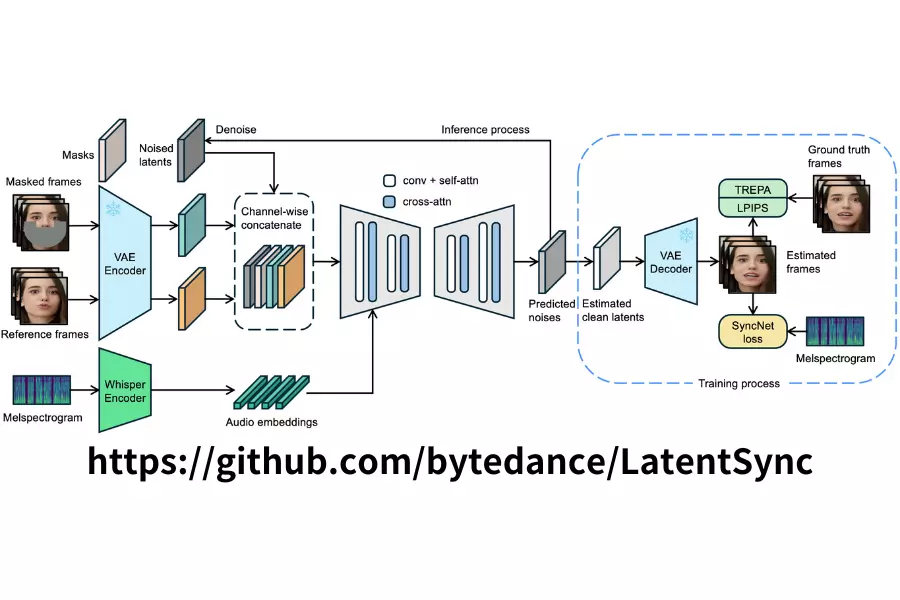
LatentSync:突破性的 AI 口型同步技術,讓影音製作更上一層樓 在影音內容製作領域中,口型同步一直是個重要且具有挑戰性的問題。LatentSync 作為一個創新的端到端口型同步...

Gemini的重大升級:1.5 Flash帶來更快回應、擴展訪問等功能 Google宣布Gemini人工智能助手的重大更新,包括在40多種語言和230多個國家和地區推出1.5 Flash版本,...
Google Gemini 2.5 Pro API 定價公布:開發者熱議,使用量激增 80% Google 正式公布了備受期待的 Gemini 2.5 Pro API 定價方案。雖然價格...

打造智慧對話:DMflow.chat 助您輕鬆建立機器人(什麼是dmflow.chat) DMflow.chat 是一個功能強大的多管道問答機器人平台,結合了大型語言模型 (LLM) 的...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.