DMflow.chat
廣告
全能 DMflow.chat:多平台整合、持久記憶與靈活客製欄位,無需額外開發即可連接資料庫與表單。更支援真人與 AI 的無縫切換,網頁互動加 API 輸出,一步到位!
你知道嗎?OpenAI 的 Sora,一款令人驚艷的視訊生成模型,訓練成本動輒上百萬美元,被譽為視訊生成界的「勞斯萊斯」。但現在,Luojian 科技帶來了平價又強悍的挑戰者 —— Open-Sora 2.0!
只花了 20 萬美元(約等同於 224 張 GPU 的計算力),就成功訓練了一個擁有 110 億參數 的商業級視訊生成模型。這不只是讓人跌破眼鏡,更像是用平價家用車的成本打造了一輛賽車!
別以為便宜就代表妥協。Open-Sora 2.0 的實力可不是說說而已。
在權威視訊評測指標 VBench 和使用者偏好測試中,它的表現穩穩咬住業界標竿,包括 OpenAI 的 Sora,以及騰訊的 混元視頻(HunyuanVideo)與擁有 300 億參數 的 Step-Video。
最讓人驚艷的是:
這是一場真正的平價革命 — 花更少的錢,達到接近甚至超越頂級模型的效果。
你可能會問:這麼便宜,效果還這麼好,怎麼做到的?
Open-Sora 2.0 的成功關鍵,來自幾個核心策略:
為了解決影片生成耗時過長的痛點,Open-Sora 團隊還訓練了一個 高壓縮影片自動編碼器(4×32×32),把生成 768px、5 秒影片的推理時間,從 30 分鐘縮短到不到 3 分鐘。
這表示,不用再等半個小時才能看到成果,未來我們可能在幾分鐘內,就能生成高品質影片內容!
真正讓人感動的是,Open-Sora 2.0 不只開源模型權重和程式碼,連完整的訓練流程都公開了。
很多技術團隊選擇開源模型但保留細節,然而 Open-Sora 的透明度讓全球研究者與開發者,都有機會參與並推動視訊生成技術的發展。
事實上,根據第三方統計:
這不只是技術上的突破,更是一場開源文化的勝利。
Luojian 科技推出的 Open-Sora 2.0,不僅成本低、效能強,還真正秉持開源精神,讓更多人有機會參與 AI 視訊生成的前線研究。
它讓視訊生成技術,不再是巨頭獨享的高牆花園,而是一個開放共創的實驗室。
也許,有一天,你我都能用自己的電腦,創作出媲美好萊塢的 AI 動畫短片。
想親自體驗或參與這場開源革命嗎?以下是資源連結:
🔗 GitHub 開源庫: Open-Sora 專案
📄 技術報告: Open-Sora 2.0 技術報告
準備好了嗎?讓我們一起站在巨人的肩膀上,改變未來的視訊生成世界!
全能 DMflow.chat:多平台整合、持久記憶與靈活客製欄位,無需額外開發即可連接資料庫與表單。更支援真人與 AI 的無縫切換,網頁互動加 API 輸出,一步到位!
Google Veo 2 登陸 AI Studio!免費試玩,人人都能變身 AI 導演? Google 最新的 AI 影片生成模型 Veo 2 終於在 AI Studio 開放免費試用了...
MuseTalk 深入解析:騰訊音樂打造的即時高傳真 AI 唇形同步神器 探索由騰訊音樂 Lyra Lab 開發的 MuseTalk 技術。了解這款開源 AI 模型如何實現即時、高品質的...

BEN2:精準影像前景分割的 AI 解決方案 在影像處理領域,如何快速且準確地去除背景,一直是業界關注的重點。傳統方法依賴綠幕技術或手動摳圖,耗時且成本高昂。如今,BEN2 (Backg...

探索 FaceFusion 的奇幻世界 - 換臉AI 本次介紹將深入探討人臉融合技術 (FaceFusion) 的原理、應用及未來發展趨勢。我們將從人臉檢測、特徵提取到圖像融合等技術層面...

TransPixar:Adobe 最新突破性透明影片生成技術 前言 在影片生成技術快速發展的今日,Adobe 推出了革命性的 TransPixar 技術,這項創新不僅能透過文字和圖像生...
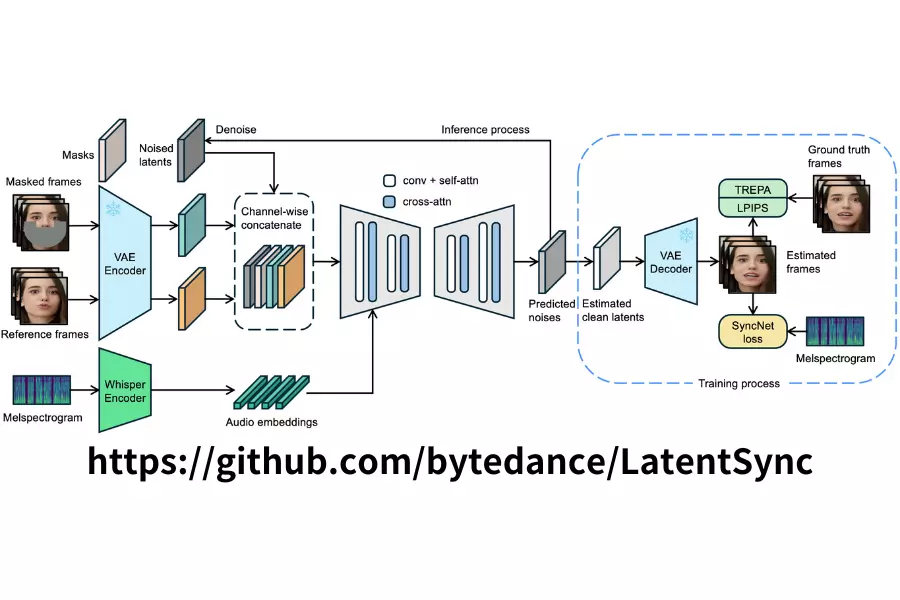
LatentSync:突破性的 AI 口型同步技術,讓影音製作更上一層樓 在影音內容製作領域中,口型同步一直是個重要且具有挑戰性的問題。LatentSync 作為一個創新的端到端口型同步...
開源 AI 音樂革命!YuE 模型正式發布,生成專業級人聲與伴奏 YuE:AI 音樂創作新時代的來臨 由 香港科技大學 與 DeepSeek 共同研發的 開源音樂生成模型 YuE 正式發布,...
Manus AI 系統被破解?官方正式回應來了 Manus 是什麼?為什麼會引發這麼大的關注? 最近,一款名為 Manus 的全能型 AI 代理人產品橫空出世,不僅技術表現亮眼,還因採取邀請...
Elon Musk 與 xAI 正式發布 Grok3:以思維鏈推理技術引領新一代 AI 革新 Elon Musk 所屬的 xAI 正式推出最新 AI 模型 Grok3,此次發布聚焦於技術...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.