
DMflow.chat
廣告
DMflow.chat:智慧整合,創新溝通!除了持久記憶與客製欄位外,更支持真人與 AI 的靈活轉換,無縫連接資料庫與表單,讓網頁互動更靈活高效。
在影片生成技術快速發展的今日,Adobe 推出了革命性的 TransPixar 技術,這項創新不僅能透過文字和圖像生成具有透明背景的影片,更為數位內容創作開創了全新可能。

TransPixar 最大的突破在於能夠生成包含 alpha 通道(透明度)的 RGBA 影片。這項技術特別擅長:
TransPixar 採用了創新的技術架構:
TransPixar 團隊計劃進一步:
TransPixar 的獨特之處在於其能夠生成具有專業級透明度的影片,這在現有的文字轉影片技術中是一大突破。
TransPixar 特別適合視覺特效藝術家、數位內容創作者以及需要製作高品質透明影片的專業人士。
TransPixar 代表了影片生成技術的重要里程碑,其在透明影片生成領域的創新將為數位內容創作帶來更多可能性。隨著技術的持續發展和完善,我們期待看到更多令人驚艷的應用案例。
註:本文內容基於 Adobe Research 等機構的最新研究成果,持續更新中。欲了解更多技術細節,建議關注官方發布的完整文件。
DMflow.chat:智慧整合,創新溝通!除了持久記憶與客製欄位外,更支持真人與 AI 的靈活轉換,無縫連接資料庫與表單,讓網頁互動更靈活高效。
Google Veo 2 登陸 AI Studio!免費試玩,人人都能變身 AI 導演? Google 最新的 AI 影片生成模型 Veo 2 終於在 AI Studio 開放免費試用了...
MuseTalk 深入解析:騰訊音樂打造的即時高傳真 AI 唇形同步神器 探索由騰訊音樂 Lyra Lab 開發的 MuseTalk 技術。了解這款開源 AI 模型如何實現即時、高品質的...
挑戰 Sora?Luojian 科技開源 Open-Sora 2.0 視訊生成模型 — 更便宜、更快、更強! 開頭 — Sora 太貴?Open-Sora 2.0 來了! 你知道嗎?OpenA...

BEN2:精準影像前景分割的 AI 解決方案 在影像處理領域,如何快速且準確地去除背景,一直是業界關注的重點。傳統方法依賴綠幕技術或手動摳圖,耗時且成本高昂。如今,BEN2 (Backg...

探索 FaceFusion 的奇幻世界 - 換臉AI 本次介紹將深入探討人臉融合技術 (FaceFusion) 的原理、應用及未來發展趨勢。我們將從人臉檢測、特徵提取到圖像融合等技術層面...
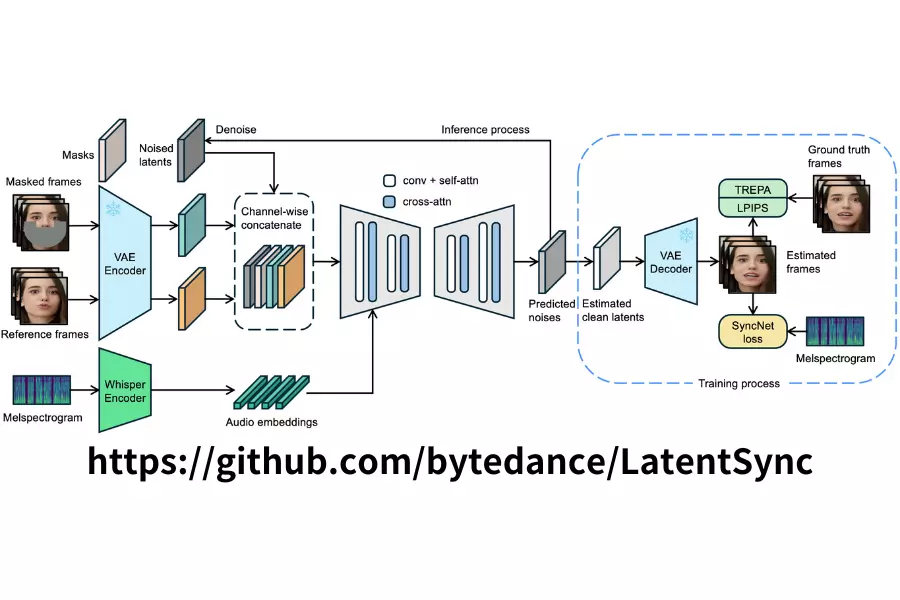
LatentSync:突破性的 AI 口型同步技術,讓影音製作更上一層樓 在影音內容製作領域中,口型同步一直是個重要且具有挑戰性的問題。LatentSync 作為一個創新的端到端口型同步...
復旦大學聯手階躍星辰!OmniSVG 橫空出世,AI 向量圖生成要變天了? 聽說過用 AI 一句話生成向量圖 (SVG) 嗎?復旦大學和階躍星辰合作的 OmniSVG 模型來了!它不只能...
Google 開源最新多模態模型 Gemma-3:效能卓越、運算成本降十倍 🚀 開啟 AI 新紀元:Google 推出開源多模態大模型 Gemma-3 Google 執行長 Sundar P...

Llama 3.2:革命性邊緣AI和視覺模型,開放且可自訂 描述 Meta推出Llama 3.2,帶來小型視覺語言模型和輕量級文本模型,顛覆邊緣運算與視覺AI領域。本文深入探討新模型的特點、應...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.