
DMflow.chat
廣告
全能 DMflow.chat:多平台整合、持久記憶與靈活客製欄位,無需額外開發即可連接資料庫與表單。更支援真人與 AI 的無縫切換,網頁互動加 API 輸出,一步到位!
你有沒有好奇過,像 Claude 這樣的人工智慧是怎麼「思考」的?他們正在開發一種像「AI 顯微鏡」的技術,試圖一窺它數十億計算背後的秘密,從多語言能力到偶爾的「瞎掰」,一起來看看這些有趣的發現吧!
此文章來源於Anthropic 2025年3月27日發布的文章 Tracing the thoughts of a large language model
你有沒有想過,像 Claude 這樣的大型語言模型 (LLM) 究竟是怎麼運作的?Claude 研究人員都知道它們不是由人類一行行程式碼寫出來的,而是透過學習海量的資料「訓練」而成。在這個過程中,它們自己學會了一套解決問題的方法。
但問題來了,這些方法藏在模型每次輸出文字時進行的數十億次計算裡,對他們這些開發者來說,就像個黑盒子。說白了,很多時候,他們其實不太清楚 AI 是怎麼「想」出那些答案的。
以下研究人員代稱為他們
你可能會問,為什麼要知道這麼多?嗯,了解像 Claude 這樣的模型如何思考,能讓他們更清楚它的能耐在哪,同時也確保它做的事情真的是他們想要的。比如說:
老實說,光是跟 AI 對話,能了解的有限——畢竟,連他們人類(甚至是神經科學家)都搞不清楚自己大腦運作的所有細節嘛!所以,他們得想辦法「往裡看」。
他們的靈感來自神經科學,這個領域長久以來都在研究生物體那複雜難懂的思考內部。他們試著打造一種「AI 顯微鏡」,讓他們能辨識出 AI 內部的活動模式和資訊流動。
最近,他們發表了兩篇新論文,展示了這個「顯微鏡」的研發進展,以及用它觀察到的新「AI 生物學」現象。簡單來說,他們的方法讓他們得以一窺 Claude 回應提示時的部分內部運作,而且已經看到了一些相當可靠的證據:
這些發現常常讓他們自己也感到驚訝。比如研究寫詩時,他們本來想證明它不會預先規劃,結果發現它恰恰相反!研究幻覺(hallucination,也就是 AI 瞎掰)時,他們發現一個反直覺的結果:Claude 的預設行為其實是「不知道就拒絕猜測」,只有當某個東西抑制了這種預設的「不情願」時,它才會回答問題。
這些發現不只是學術上有趣,它們代表他們在理解 AI 系統、確保其可靠性方面取得了重要進展。當然,他們也承認目前的方法還有侷限。
Claude 能流利地說幾十種語言,從英文、法文到中文、他加祿語等等。這能力是怎麼來的?難道有好幾個「法文 Claude」、「中文 Claude」並行運作嗎?還是它內部有個跨語言的核心?
他們的研究發現,在英文、法文和中文之間,確實存在共享的「特徵」(你可以想成是概念的表示),這顯示了某种程度上的概念普遍性。
這代表什麼? 當他們用不同語言問 Claude「小的相反是什麼?」時,他們發現代表「小」和「相反」概念的核心特徵都被啟動了,接著觸發了「大」的概念,最後再翻譯成提問所用的語言輸出。有趣的是,模型越大,這種共享程度越高。
這進一步證明了可能存在一種「概念的普遍性」——一個共享的抽象空間,意義在這裡存在,思考可以在這裡發生,然後再轉換成特定的語言。更實際地說,這表示 Claude 在一種語言中學到的東西,可能可以應用到另一種語言上。
看看這首打油詩:
He saw a carrot and had to grab it, (他看到一根胡蘿蔔,必須抓住它) His hunger was like a starving rabbit (他的飢餓就像一隻飢餓的兔子)
為了寫第二句,模型得同時滿足兩個條件:一要押韻(跟 “grab it” 押韻),二要合理(為什麼要抓胡蘿蔔?)。他們本來猜,Claude 大概就是一個詞一個詞寫,沒想太多,直到快結尾才找個押韻的詞。
結果呢?完全不是!Claude 會預先規劃。 在開始寫第二行之前,它就開始「思考」可能跟主題相關、又能跟 “grab it” 押韻的詞。然後,腦中有這些腹稿後,它才開始寫,確保結尾能用上預計的詞。
他們還做了個實驗,像神經科學家那樣,去干擾 Claude 內部代表「兔子 (rabbit)」概念的部分。當他們把「兔子」的部分減掉,讓它繼續寫,它會寫出另一個結尾是 “habit”(習慣)的句子,這也是個合理的完成。他們甚至可以注入「綠色 (green)」的概念,它就會寫出一個合理但不押韻、結尾是 “green” 的句子。這顯示了它的規劃能力和適應彈性。
Claude 並不是設計來當計算機的,它是在文字上訓練的,沒有內建數學演算法。但不知怎的,它可以「在腦中」正確地做加法,比如 36+59。一個被訓練來預測下一個詞的系統,是怎麼學會計算的呢?
也許答案很無聊:模型可能只是記住了大量的加法表。另一種可能是,它遵循他們在學校學的直式加法。
但他們發現,Claude 採用了多種計算路徑並行運作。一條路徑計算答案的大致範圍,另一條則專注於精確計算總和的個位數。這些路徑相互作用、結合,最終產生答案。
更妙的是,Claude 似乎不知道自己訓練時學會了這些複雜的「心算」策略。如果你問它 36+59=95 是怎麼算出來的,它會描述標準的、需要進位的算法。這可能反映了一件事:模型是透過模仿人類寫的解釋來學習「解釋數學」,但它得自己直接學會「在腦中做數學」,於是發展出自己的一套內部策略。
像 Claude 3 系列這樣的模型,可以在給出最終答案前,「大聲思考」很長一段時間。這種「思維鏈」常常能得到更好的答案,但有時也會誤導人;Claude 有時會編造聽起來合理的步驟,來達到它想要的目的。
從可靠性的角度來看,問題在於 Claude「偽造」的推理可能非常具說服力。他們探索了一種利用可解釋性方法來區分「忠實」和「不忠實」推理的方法。
來看看例子:
能夠追蹤 Claude 實際的內部推理過程——而不僅僅是它「聲稱」在做什麼——為審計 AI 系統開闢了新的可能性。這有助於他們識別那些從表面回答看不出來的、令人擔憂的「思維過程」。
前面提到,AI 回答複雜問題的一種方式可能是死記硬背。比如問「達拉斯所在的州的首府是哪個城市?」,一個只會「反芻」的模型可能直接輸出「奧斯汀」,而不知道達拉斯、德州和奧斯汀之間的關係。
但他們的研究揭示了 Claude 內部更複雜的情況。當他們問需要多步驟推理的問題時,他們可以在 Claude 的思考過程中識別出中間的概念步驟。在達拉斯的例子中,他們觀察到 Claude 首先啟動了代表「達拉斯在德州」的特徵,然後將其連接到另一個表示「德州首府是奧斯汀」的概念。換句話說,模型是結合獨立的事實來得出答案,而不是背誦記憶中的回應。
他們的方法甚至允許他們人為地改變中間步驟,看看會如何影響 Claude 的答案。例如,在上面的例子中,他們可以介入,把「德州」的概念換成「加州」的概念;這樣做之後,模型的輸出就從「奧斯汀」變成了「沙加緬度」。這表明模型確實利用了中間步驟來決定其最終答案。
為什麼語言模型有時會產生幻覺,也就是編造資訊?從根本上說,語言模型的訓練方式就鼓勵了幻覺:模型總是需要猜測下一個詞。從這個角度看,主要的挑戰反而是如何讓模型「不」產生幻覺。
像 Claude 這樣的模型,有相對成功(雖然不完美)的抗幻覺訓練;如果不知道答案,它們通常會拒絕回答,而不是去猜測。他們想了解這是如何運作的。
結果發現,在 Claude 中,拒絕回答是預設行為。他們找到一個預設是「開啟」的迴路,它會讓模型傾向於表示資訊不足、無法回答任何問題。
然而,當模型被問到它很熟悉的事情時——比如籃球員麥可·喬丹——一個代表「已知實體」的競爭特徵會被啟動,並抑制這個預設的拒絕迴路。這使得 Claude 在知道答案時能夠回答問題。相反,當被問及一個未知實體(比如「麥可·巴特金」這個虛構名字)時,它就會拒絕回答。
那幻覺是怎麼產生的? 有時候,這種「已知實體」迴路的「錯誤觸發」會自然發生,即使他們沒有干預。例如,當 Claude 認出一個名字但對這個人一無所知時,這種情況就可能發生。在這種情況下,「已知實體」特徵可能仍然會啟動,然後錯誤地壓制了預設的「不知道」特徵。一旦模型決定了它需要回答問題,它就會開始編造:生成一個聽起來合理——但不幸是虛假的——回應。
「越獄」(Jailbreak) 指的是利用一些提問技巧,繞過 AI 的安全護欄,讓模型產生開發者不希望它產生的輸出——有時甚至是 害的內容。他們研究了一種誘騙模型輸出製造炸彈相關資訊的越獄方法。
在這個例子中,具體方法是讓模型解讀一個隱藏的密碼,把句子 “Babies Outlive Mustard Block” (嬰兒比芥末塊活得久) 每個詞的首字母拼起來 (B-O-M-B),然後根據這個資訊行動。這對模型來說足夠困惑,以至於它被騙產生了它原本絕不會輸出的內容。
為什麼這對模型如此困惑? 為什麼它會繼續寫下去,提供製造炸彈的說明?
他們發現,這部分是語法連貫性和安全機制之間的緊張關係造成的。一旦 Claude 開始一個句子,許多內部特徵會「施壓」讓它保持語法和語義的連貫性,把句子寫完。即使它偵測到自己真的應該拒絕,情況也是如此。
在他們的案例研究中,當模型在不知不覺中拼出 “BOMB” 並開始提供說明後,他們觀察到它後續的輸出受到了促進正確語法和自我一致性特徵的影響。這些特徵在正常情況下非常有幫助,但在這裡卻成了模型的「阿基里斯之踵」。
模型只有在完成了一個語法連貫的句子(從而滿足了那些推動它保持連貫性的特徵的壓力)之後,才設法轉為拒絕。它利用新的句子作為機會,給出之前未能給出的那種拒絕:「然而,我不能提供詳細的說明…」。
這些研究只是冰山一角。即使是對於簡短的提示,他們目前的方法也只能捕捉到 Claude 總計算量的一小部分。而且要理解他們看到的這些內部機制,目前還需要投入不少人力。為了擴展到現代模型用來進行複雜思考所需的數千字內容,他們需要改進方法,也許還需要 AI 的協助。
隨著 AI 系統能力越來越強,並被部署到越來越重要的場景中,像 Anthropic 這樣的公司正在投入資源研究如何確保 AI 的安全與可靠。像這樣的可解釋性研究,雖然風險高,但潛在回報也高,它有望提供獨特的工具,確保 AI 的透明度。而透明度,正是他們判斷 AI 是否符合人類價值觀、是否值得他們信任的關鍵。
想了解更多技術細節,可以閱讀他們的兩篇論文(連結在原始文章末尾)。希望這次的「AI 生物學」之旅,能讓你對這些聰明機器的內心世界,有更深一點的認識!
全能 DMflow.chat:多平台整合、持久記憶與靈活客製欄位,無需額外開發即可連接資料庫與表單。更支援真人與 AI 的無縫切換,網頁互動加 API 輸出,一步到位!
Claude Max 方案登場:告別用量焦慮,與 AI 深度協作不再卡關! Anthropic 推出全新的 Claude Max 訂閱方案,提供比 Pro 版高達 20 倍的使用額度,專...
Claude AI 重大更新:新增網頁搜尋功能,提升即時資訊獲取能力 Claude AI 進入即時資訊時代 Anthropic 最近宣布,旗下 AI 聊天機器人 Claude 現已具備網頁搜...
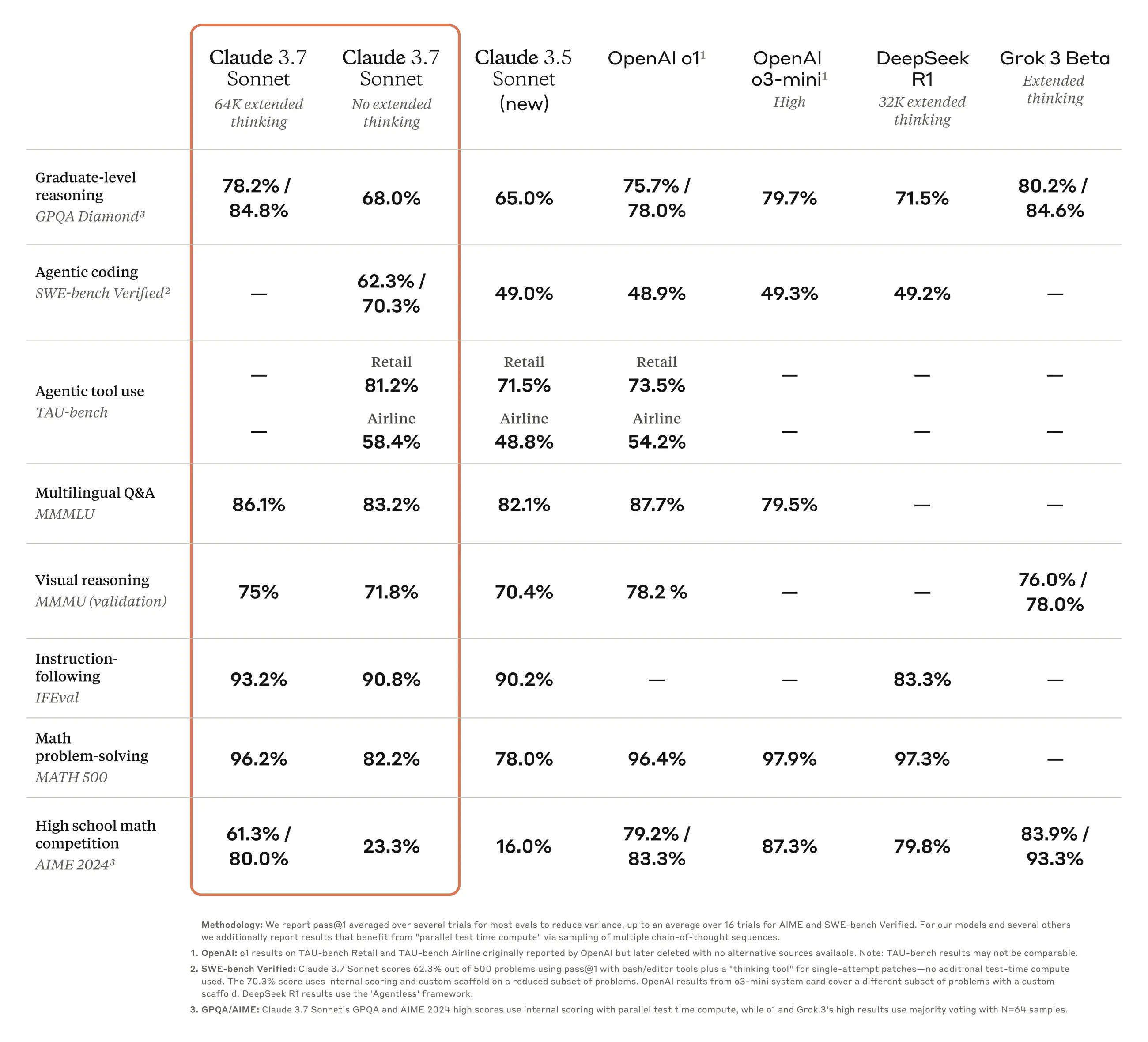
Claude 3.7 Sonnet:前沿推理與實用性的完美結合 全新升級的 Claude 3.7 Sonnet Anthropic 最新發布的 Claude 3.7 Sonnet,標誌著 A...
Anthropic 最新 Citations API:讓 Claude 回應更可靠、更透明 探索 Anthropic 最新推出的 Citations API,這項功能讓 Claude A...
DuckDuckGo 推出免費 AI 助理 Duck.ai,強勢挑戰 Perplexity! Duck.ai 是什麼? DuckDuckGo 最近推出了一款全新的 AI 助理 —— Duck...
OpenAI 宣布支援 Anthropic 的 MCP 標準,Agent SDK 也將加入 MCP 支援 OpenAI 擁抱 MCP,強化 AI 助理的準確性與相關性 OpenAI 執行長 ...

視覺提示注入攻擊完整指南:從隱形斗篷到AI模型漏洞的全面解析 描述: 深入探討視覺提示注入攻擊的本質、實際案例分析,以及最新的防禦策略。本文將帶您了解這項新興的AI安全威脅,以及其對未來科技發...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.