Claude 3.7 Sonnet:前沿推理與實用性的完美結合
全新升級的 Claude 3.7 Sonnet
Anthropic 最新發布的 Claude 3.7 Sonnet,標誌著 AI 邏輯推理與實用性的一次重大突破。作為首款具備 混合推理能力 的模型,Claude 3.7 Sonnet 不僅可以即時生成答案,也能在延展思維模式下進行深度推理,根據使用者需求,在速度與精確度之間達成微妙平衡。
本次更新特別針對程式開發與推理能力進行優化,並同步推出 Claude Code——一款專為代理式程式設計打造的命令列工具。這項工具目前處於研究預覽階段,可讓開發者直接透過終端機與 Claude 協作,處理從程式碼檢索到版本控制等一系列工程任務。
Benchmark:超越前代模型與競爭對手
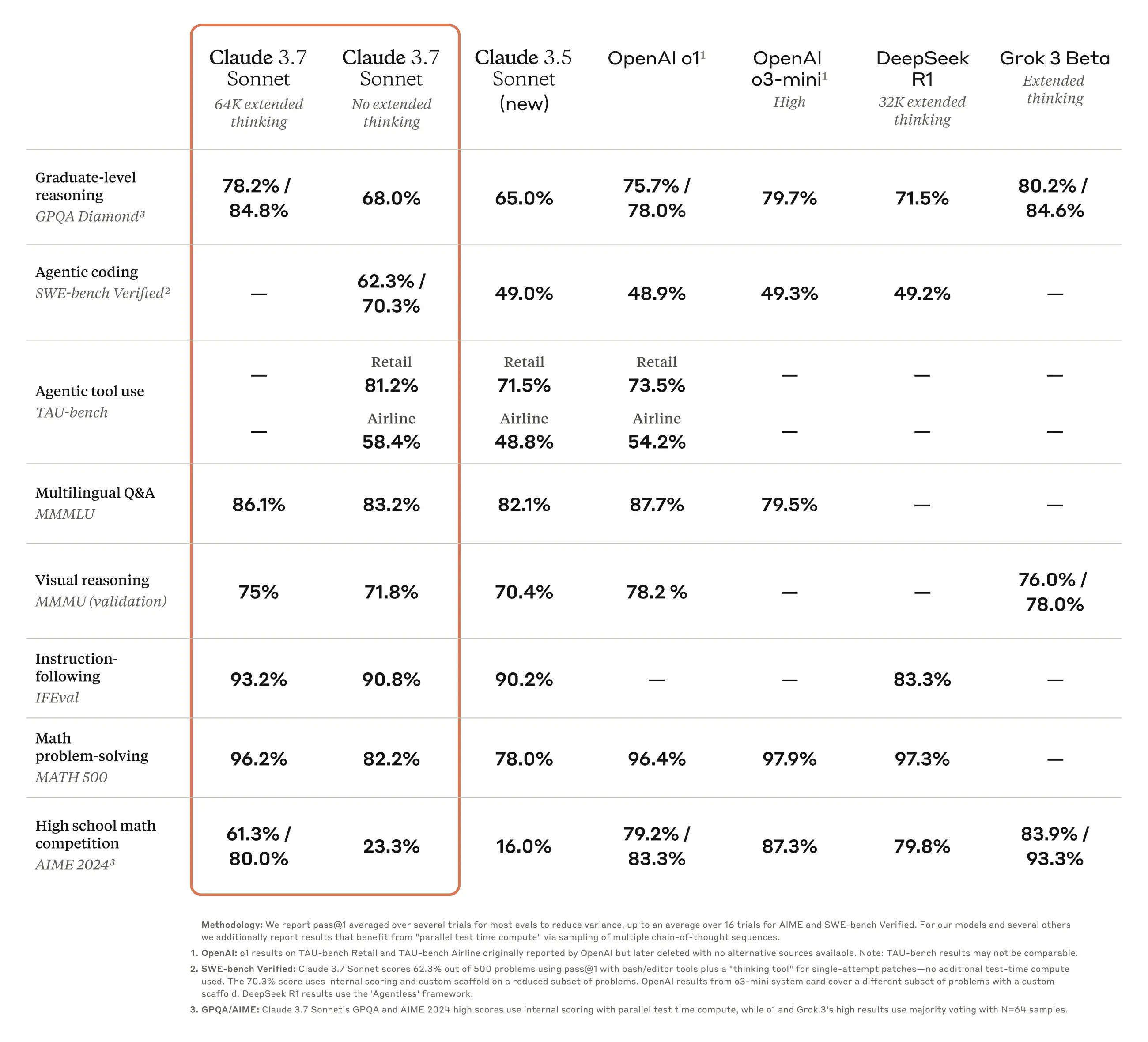
從最新的 Benchmark 測試結果來看,Claude 3.7 Sonnet 在多項指標上的表現相較於 Claude 3.5 以及其他競爭模型,都展現了卓越的進步與領先地位。
🎯 推理與理解能力
- 研究生級推理測試 (GPQA Diamond):標準模式下達到 78.2% 的正確率,而在延展思維模式下則提升至 84.8%,超越 OpenAI 的 GPT-4 系列模型。
- 多語言問答測試 (MMLU):取得 86.1% 的成績,展現 Claude 3.7 在跨語言理解與推理上的穩健表現。
🧑💻 程式設計與代理能力
- 代理式程式設計測試 (SWE-bench Verified):Claude 3.7 Sonnet 於代理程式碼撰寫任務中達到 62.3% / 70.3% 的準確度,遠高於 Claude 3.5。
- 工具使用評估 (TAU-bench):在零售與航空領域的代理測試中,分別取得 81.2% 與 58.4% 的成績,證明了其在複雜工具與環境互動上的強大能力。
📚 數理與邏輯推理
- 數學解題測試 (Math 500):在標準模式下正確率為 96.2%,延展模式更提升至 82.2%,顯示其在數學與邏輯推理上的深厚實力。
- 高中數學競賽測試 (AIME 2024):從標準模式的 61.3% 一舉突破至延展思維的 80.0%,進一步鞏固了 Claude 3.7 在高難度數學問題上的競爭優勢。
圖片來源: https://www.anthropic.com/news/claude-3-7-sonnet
Claude Code:打造更智慧的程式設計夥伴
除了模型本身的強化,Claude 3.7 Sonnet 也同步推出 Claude Code,專為代理式開發設計。Claude Code 能夠協助開發者:
- 搜尋與閱讀程式碼
- 編輯與重構檔案
- 撰寫與執行測試案例
- 提交並推送程式碼至 GitHub
- 使用命令列工具整合開發流程
在內部測試中,Claude Code 能夠在單次執行下完成過往需要 45 分鐘以上人工處理 的開發任務,大幅減少開發週期與工作量。
未來展望
Claude 3.7 Sonnet 與 Claude Code 不僅提升了 AI 模型的推理與程式設計能力,更朝向 智慧化代理系統 邁進。Anthropic 的核心理念是讓 AI 不僅成為快速生成內容的工具,更是能夠協作思考、主動解決問題的夥伴。
隨著 Claude 3.7 的發布,我們期待這款模型在企業應用、研究開發與技術創新等領域帶來嶄新的可能性。
想了解更多?歡迎體驗 Claude 3.7 Sonnet,探索 AI 在推理與代理領域的無限潛能。