
Article Summary
In the development of artificial intelligence, a significant milestone has been reached: the new o3 series model demonstrates unprecedented excellence in mathematical operations and programming, even surpassing human performance in some tests. This article will delve into the groundbreaking progress of the o3 series and discuss its profound impact on the development of artificial intelligence.
Major Release Event Recap
During the 12-day grand release event, OpenAI not only introduced the first reasoning model, o1, but also announced the upcoming launch of the highly promising o3 and o3 mini. This release garnered unprecedented attention, marking a significant turning point in AI technology development.
What is o3
o3 is OpenAI’s latest cutting-edge model, designed to significantly enhance reasoning capabilities in various complex tasks. It was released alongside its smaller version, o3 mini, focusing on solving challenges in coding, mathematics, and general intelligence. o3’s standout feature is its emphasis on more challenging benchmark tests, which assess the model’s reasoning abilities in ways that were previously unattainable. OpenAI highlighted o3’s improvements over o1, positioning it as a more powerful system for solving complex problems.
Breakthrough Achievements of the o3 Model
The o3 model has made significant breakthroughs in several key areas, particularly excelling in programming and mathematics:
1. Programming Capability Leap:
- SWE-bench Verified Test: o3 achieved an accuracy rate of 71.7%, far surpassing o1’s 48.9%, with an improvement of over 20 percentage points. This indicates a qualitative leap in o3’s ability to understand and generate code. This test evaluates the model’s performance in real software engineering tasks, and o3’s excellent score means it has greater potential in practical applications. The test simulates real software engineering scenarios, assessing the model’s ability to understand and modify code. An accuracy rate of 71.7% proves that o3 is more reliable in handling actual programming tasks.
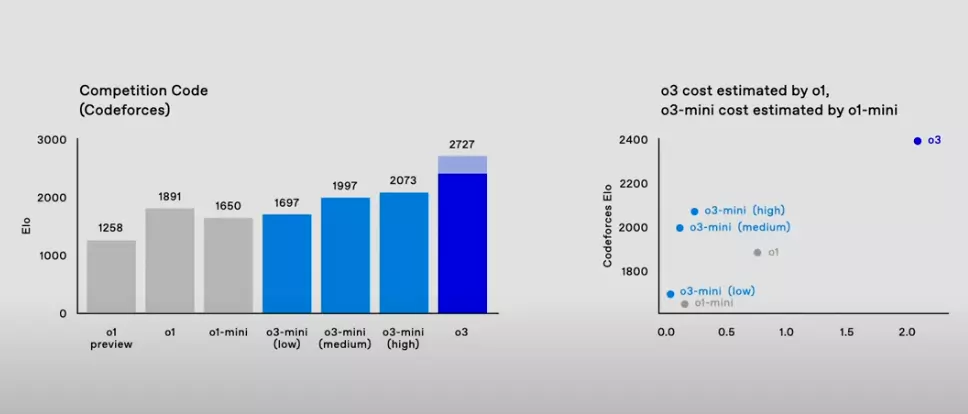
- Codeforces Platform: o3 scored 2727 ELO points on the Codeforces platform, while o1 scored 1891 points, showing a significant improvement. Codeforces is a platform for competitive programming, and ELO scores are used to measure the programming ability of players (or models). o3’s high score indicates that it has reached an extremely high level in algorithm design, code optimization, and problem-solving, even comparable to top human programmers. Data shows that a score above 2400 on Codeforces already surpasses 99% of human engineers, and o3’s 2727 points are close to the world’s top level, indicating its strong competitiveness in algorithm competitions.
2. Mathematical Computation Leap:
- AIME (American Invitational Mathematics Examination): o3 achieved an excellent score of 96.7% in the AIME test, while o1 scored 83.3%. AIME is a high-difficulty mathematics competition aimed at high school students who excel in the American Mathematics Olympiad (USAMO). o3’s high score indicates its exceptional ability to solve complex mathematical problems. Missing only one question further highlights its strong mathematical reasoning ability. AIME tests high-difficulty mathematical problems at the high school level, and o3’s high score proves its excellence in mathematical understanding and problem-solving techniques.
- GPQA Diamond Test: o3 scored 87.7% in this test, 10 percentage points higher than o1. GPQA Diamond is a set of graduate-level biology, physics, and chemistry problems designed to evaluate the model’s knowledge and reasoning abilities in scientific fields. o3’s excellent performance indicates significant progress in understanding and applying scientific knowledge, approaching or even surpassing human expert levels. This test is very challenging, covering professional knowledge across multiple disciplines, and o3’s high score reflects its broad knowledge and strong reasoning abilities in scientific fields.
- EpochAI Frontier Math Test: This is another important mathematical benchmark test, where o3 solved 25.2% of the problems, while all other models scored below 2%. This indicates that o3 has a unique advantage in handling extremely complex and abstract mathematical problems, which even top mathematicians might take hours or days to solve. This test aims to assess the model’s ability to handle frontier mathematical problems, and o3’s outstanding performance indicates its great potential in solving highly complex and abstract mathematical challenges.
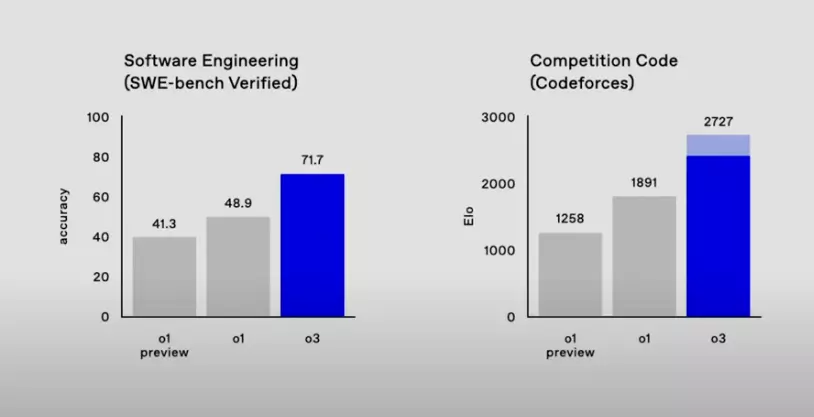
Image Source: https://www.youtube.com/live/SKBG1sqdyIU
From the above comparison, it is clear that o3 has shown significant progress in coding compared to o1.
- Programming: o3’s significant improvements in SWE-bench and Codeforces demonstrate its advantages in real programming tasks and algorithm competitions.
o1 vs o3 Comparison
o3 has shown significant improvements over o1 in all aspects, particularly achieving breakthroughs in programming and mathematical computation. These advancements not only represent a huge leap in AI technology but also indicate broader application prospects for AI in solving complex problems. The following table summarizes the main differences between the two:
| Feature | o1 | o3 |
|---|---|---|
| Main Objective | Demonstrate general reasoning ability | Further enhance reasoning ability, especially in programming, mathematics, and general intelligence |
| SWE-bench Accuracy | 48.9% | 71.7% |
| Codeforces ELO Score | 1891 | 2727 |
| Open for Use | Released | Currently undergoing safety testing, not yet fully available for use |
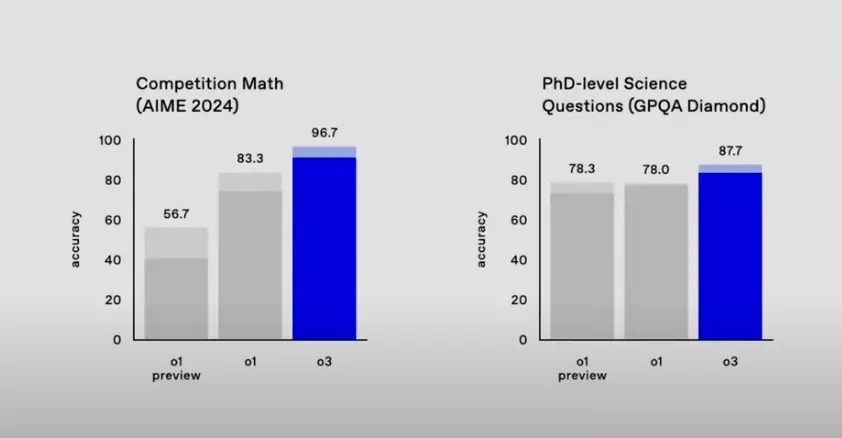
Image Source: https://www.youtube.com/live/SKBG1sqdyIU
From the above comparison, it is clear that o3 has shown significant progress in mathematics and science compared to o1.
- Mathematics: o3’s near-perfect performance in AIME proves its exceptional ability to solve complex mathematical problems.
- Science: o3’s improvement in the GPQA Diamond test shows significant progress in understanding and applying scientific knowledge.
| Field | Evaluation Standard | o1 | o3 | Improvement |
|---|---|---|---|---|
| Mathematics | AIME Accuracy | 83.3% | 96.7% | 13.4% |
| Science | GPQA Diamond Accuracy | ~78% | 87.7% | ~10% |
EpochAI Frontier Math: o3’s Breakthrough in Research-Level Mathematical Problems
EpochAI Frontier Math is a benchmark test specifically designed to evaluate AI models’ performance on extremely complex and abstract mathematical problems. These problems are so difficult that even top mathematicians might take hours or days to solve. Therefore, achieving any significant results in this test represents a major breakthrough in AI’s mathematical reasoning capabilities.
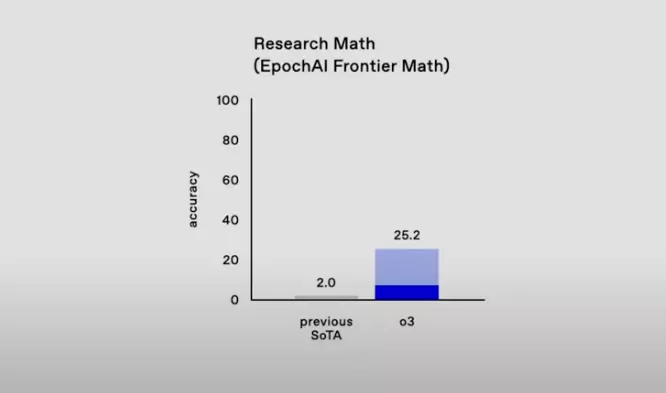
- Previous State of the Art (SOTA): Accuracy was only 2.0%. This means that the best models before could hardly solve any problems in this test.
- o3: Accuracy significantly increased to 25.2%. Compared to the previous state of the art, this is a huge leap, showing that o3 has a unique advantage in handling extremely complex and abstract mathematical problems.
Significance of EpochAI Frontier Math:
The importance of the EpochAI Frontier Math test lies in its challenge to AI models’ ability to handle problems beyond the scope of traditional mathematics. These problems typically require:
- Highly Abstract Thinking: The description and solution of the problems may involve very abstract mathematical concepts and structures.
- Multi-step Reasoning: Solving these problems usually requires multiple steps of logical reasoning and mathematical computation.
- Creative Problem Solving: Some problems may not have a clear solution method, requiring the model to use creative thinking to find solutions.
o3’s 25.2% accuracy in the EpochAI Frontier Math test not only far exceeds the previous state of the art but, more importantly, demonstrates AI’s potential in handling such high-difficulty mathematical problems. This achievement could have a profound impact on future mathematical research, scientific discovery, and other fields requiring complex reasoning abilities.
The EpochAI Frontier Math test highlights o3’s breakthrough in research-level mathematical problems. Compared to the previous state of the art, o3’s performance has significantly improved, proving that AI has made major progress in handling extremely complex and abstract mathematical problems. This achievement not only has important academic significance but also opens up new possibilities for AI applications in science and engineering.
In extremely difficult mathematical problems, o3 far surpasses all previous AI models, representing a major breakthrough in AI’s mathematical reasoning capabilities.
o3’s Breakthrough in ARC AGI
One of o3’s most notable achievements is its excellent performance in the ARC AGI benchmark test. ARC AGI is widely regarded as the gold standard for evaluating artificial intelligence’s general intelligence.
ARC (Abstraction and Reasoning Corpus) was developed by François Chollet in 2019, focusing on evaluating AI’s ability to learn and generalize new skills from very few examples. Unlike traditional benchmark tests that often test pre-trained knowledge or pattern recognition, ARC tasks aim to challenge models to infer rules and transformations in real-time—tasks that humans can solve intuitively but have been difficult for AI in the past.
ARC AGI is particularly challenging because each task requires different reasoning skills. Models cannot rely on memorized solutions or templates; instead, they must adapt to entirely new challenges in each test. For example, one task might involve identifying patterns in geometric transformations, while another might require reasoning about numerical sequences. This diversity makes ARC AGI an effective indicator of whether AI can truly think and learn like humans.
o3 mini: Innovative Lightweight Model
Lowering the Bar for AI Applications: Cost-Effective Reasoning Solution
- Cost-Effective Reasoning Model Solution: The main goal of o3 mini is to lower the barrier to AI applications, allowing more organizations and individuals to use advanced AI technology.
- Committed to Popularizing AI Technology: OpenAI hopes to enable small and medium-sized enterprises and individual developers to afford high-performance AI solutions through o3 mini.
- Major Breakthrough in Cost-Effectiveness: o3 mini has achieved a major breakthrough in cost-effectiveness, providing performance close to o3 at a lower cost.
Performance Evaluation: Surpassing o1 mini, Maintaining Low Costs
- Surpassing o1 mini: In multiple tests, o3 mini’s performance surpassed that of o1 mini, showing significant progress.
- Maintaining Lower Operating Costs: Despite the performance improvement, o3 mini still maintains lower operating costs, making it more attractive.
- Feasible Solution for Small and Medium-Sized Enterprises: o3 mini provides a feasible AI solution for small and medium-sized enterprises, allowing them to apply advanced AI technology within a limited budget.
Breakthrough in Innovative Benchmark Tests: Demonstrating Excellent Performance
- EpochAI Frontier Math Benchmark:
- Regarded as one of the most challenging mathematical tests.
- The o3 model achieved over 25% accuracy, far surpassing the previous state of the art.
- Demonstrates strong ability to solve complex mathematical problems.
- ARC AGI Benchmark Test Milestone:
- In high-compute settings, the o3 model achieved a score of 87.5%.
- For the first time, it surpassed the human average performance of 85%, marking an important milestone.
- Sets a new standard for AI development.
Unique Feature of o3 mini: Flexible Thinking Time
A standout feature of o3 mini is its flexible thinking time, allowing users to adjust the model’s reasoning input based on the complexity of the task.
- Simple Problems: For simpler problems, users can choose a low-input reasoning mode to maximize speed and efficiency.
- Complex Problems: For more challenging tasks, users can choose a high-input reasoning mode, allowing the model’s performance to reach levels comparable to o3, but at a cost far lower than o3.
This flexibility is particularly attractive to developers and researchers working on different use cases, as they can balance performance and cost according to their actual needs.
Safety Testing and Development Direction: Ensuring AI Reliability
- Public Safety Testing Program:
- Open to researchers for early testing eligibility to gather more feedback and make improvements.
- Implement strict safety testing procedures to ensure the model’s safety and reliability.
- Prioritize safety while enhancing model capabilities.
- Thoughtful Alignment Techniques:
- Adopt innovative safety training methods to improve the model’s accuracy in identifying safe and unsafe prompts.
- Provide more reliable safety assurances for AI development, reducing potential risks.
Frequently Asked Questions
Q1: What are the main improvements of the o3 model compared to the o1 model?
A: The o3 model has significant improvements in programming, mathematical computation, and other areas, such as a 20% increase in accuracy in the SWEET Bench test and an ELO score increase of over 800 points on the Codeforces platform.
Q2: What are the main advantages of o3 mini?
A: The main advantage of o3 mini is providing a cost-effective AI solution, maintaining lower operating costs while still outperforming o1 mini.
Q3: When can these new models be used?
A: o3 mini is expected to be released by the end of January, with the o3 model to follow. Currently, researchers can apply for early testing eligibility.
Future Outlook
With the launch of the o3 series models, AI technology will enter a new phase. We look forward to these groundbreaking advancements bringing innovation to various industries and promoting the healthy development of artificial intelligence technology.
Related Links
- OpenAI Day11: ChatGPT Desktop App Breakthrough: New Generation AI Assistant Features Fully Analyzed
- OpenAI Day10 ChatGPT Comprehensive Innovation: Phone, WhatsApp Full Integration, AI Communication Made Easier
- OpenAI Day9: Celebrating Global Developers: Enhancing Developer Experience
- OpenAI Day8: ChatGPT Search Function Now Online! Global Users Can Access Real-Time Information Queries
- OpenAI Day7: Launching “Projects” Feature Integrating Conversations and Workspaces
- OpenAI Day6: Chatbot Function Major Upgrade: Real-Time Interaction and Festive Surprises New Experience
- OpenAI Day5: Good News for Apple Device Users: ChatGPT Seamlessly Integrated into iOS, iPadOS, and macOS, Making Use More Convenient!
- OpenAI Day4: Deep Dive into OpenAI’s Canvas Feature and Applications
- OpenAI Day3: Leading Innovation! Sora Product Launch Event Highlights
- OpenAI Day2: Reinforcement Learning Fine-Tuning and Model Customization: New Trends in Future AI
- OpenAI Day1: Launching ChatGPT Pro, $200 Monthly Subscription, o1 Official Version Paid Users Can Use

DMflow.chat
Discover DMflow.chat and unlock the new era of AI-powered customer service.
Learn More
DMflow.chat
DMflow.chat: Your intelligent AI partner for exceptional customer engagement.
Learn More
scribis.app
Scribis: Subtitle editing, audio transcription, and live transcription.
Learn More
videoweaver.app
Video Weaver: Professional video editing directly in your browser. No downloads required.
Learn MoreDMflow.chat
Discover DMflow.chat and unlock the new era of AI-powered customer service.
Learn MoreDMflow.chat
DMflow.chat: Your intelligent AI partner for exceptional customer engagement.
Learn Morescribis.app
Scribis: Subtitle editing, audio transcription, and live transcription.
Learn Morevideoweaver.app
Video Weaver: Professional video editing directly in your browser. No downloads required.
Learn More