
DMflow.chat
廣告
DMflow.chat:智慧客服新時代,輕鬆切換真人與 AI!持久記憶、客製欄位、即接資料庫表單,多平台溝通,讓服務與行銷更上一層樓。
3 月 19 日,開源文字轉語音(TTS)模型 Orpheus TTS 正式亮相,迅速在技術圈引起熱議。這款模型以其接近人類的 情感表達、自然流暢的語音品質,以及 超低延遲的即時輸出 而備受矚目。Orpheus TTS 尤其適用於 即時對話場景,有望為智慧語音互動領域帶來重大突破。
這款 TTS 模型的強大之處,在於它針對 低延遲與高情感表達 進行了深度優化,主要特色包括:
<laugh>、<sigh>、<groan> 等),能夠讓語音輸出更加生動。由於超低延遲與流暢自然的語音表達,Orpheus TTS 特別適用於 即時語音對話,如 Siri、Google Assistant、ChatGPT 語音助手等。
Orpheus TTS 能夠模擬真人語調,使線上課程內容更加生動,提升學習體驗。
支援零樣本語音克隆,開發者能快速為遊戲角色、虛擬偶像、直播 AI 配音,提升互動感。
超低延遲確保對話自然流暢,讓 AI 客服不再機械生硬,能夠模擬真人客服的語調與情緒變化。
首先,Clone 官方 GitHub Repo,並安裝必要的 Python 套件:
git clone https://github.com/canopyai/Orpheus-TTS.git
cd Orpheus-TTS && pip install orpheus-speech
接下來,使用 Python 來生成語音:
from orpheus_tts import OrpheusModel
import wave
import time
model = OrpheusModel(model_name="canopylabs/orpheus-tts-0.1-finetune-prod")
prompt = "這是一個示範語音測試,讓我們看看 Orpheus TTS 的表現如何!"
start_time = time.monotonic()
syn_tokens = model.generate_speech(prompt=prompt, voice="tara")
with wave.open("output.wav", "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
total_frames = 0
for audio_chunk in syn_tokens:
frame_count = len(audio_chunk) // (wf.getsampwidth() * wf.getnchannels())
total_frames += frame_count
wf.writeframes(audio_chunk)
duration = total_frames / wf.getframerate()
end_time = time.monotonic()
print(f"生成 {duration:.2f} 秒語音,共耗時 {end_time - start_time} 秒")
在生成語音時,可以加入 情緒標籤 來改變語音表達方式。例如:
prompt = "我真的很興奮!<laugh> 這個 AI 真的太神奇了!"
syn_tokens = model.generate_speech(prompt=prompt, voice="leo")
這樣,生成的語音就會帶有笑聲,讓語氣更生動自然!
如果你希望 客製化專屬語音模型,可以透過 Hugging Face 進行微調。這裡提供簡單的微調步驟:
pip install transformers datasets wandb trl flash_attn torch
huggingface-cli login <輸入你的 Hugging Face Token>
wandb login <輸入你的 wandb Token>
accelerate launch train.py
Tip: 一般來說,約 50 個語音樣本 就能得到不錯的效果,但若要更高品質的語音建議 300 個樣本以上。
Orpheus TTS 的問世,不僅提升了語音合成的品質,更讓 AI 互動體驗更加自然生動。
🔹 即時對話 🚀 超低延遲,媲美真人語速
🔹 擬真語音 🎭 精準模擬人類情緒與語調
🔹 零樣本語音克隆 🎙️ 快速打造個性化 AI 聲音
🔹 開源 & 可微調 🔧 讓開發者能自由定制
隨著 AI 語音技術的不斷發展,Orpheus TTS 無疑將成為 開源 TTS 領域的重要里程碑。如果你想體驗更具人性的 AI 語音,那麼 Orpheus TTS 絕對值得一試! 🎤✨
此模型目前需要15 GB以上,或者使用量化後的模型,目前僅支援英語
DMflow.chat:智慧客服新時代,輕鬆切換真人與 AI!持久記憶、客製欄位、即接資料庫表單,多平台溝通,讓服務與行銷更上一層樓。
IndexTTS 登場:告別生硬發音!打造可控又高效的工業級文字轉語音系統 厭倦了 AI 語音唸錯字或語氣平淡嗎?來認識 IndexTTS!這款基於 GPT 架構的最新文字轉語音 (TT...
MegaTTS 3 橫空出世:輕量、高擬真聲音克隆,還能中英夾雜?AI 語音的新里程碑! 還在尋找那個完美的 AI 語音生成工具嗎?來認識一下 MegaTTS 3!它不僅模型輕巧、效率驚...
開源 AI 音樂革命!YuE 模型正式發布,生成專業級人聲與伴奏 YuE:AI 音樂創作新時代的來臨 由 香港科技大學 與 DeepSeek 共同研發的 開源音樂生成模型 YuE 正式發布,...
OpenAI 推出全新語音 AI 模型:gpt-4o-transcribe 及其應用前景 描述 OpenAI 近期推出了三款全新自研語音 AI 模型,包括 gpt-4o-transcribe、...
Spark-TTS:AI 驅動的語音複製與個性化新時代! 🌟 認識 Spark-TTS:讓 AI「說話」像你一樣自然 科技發展的速度讓人目不暇給,尤其是人工智慧領域。從語音助理到自動客服,A...
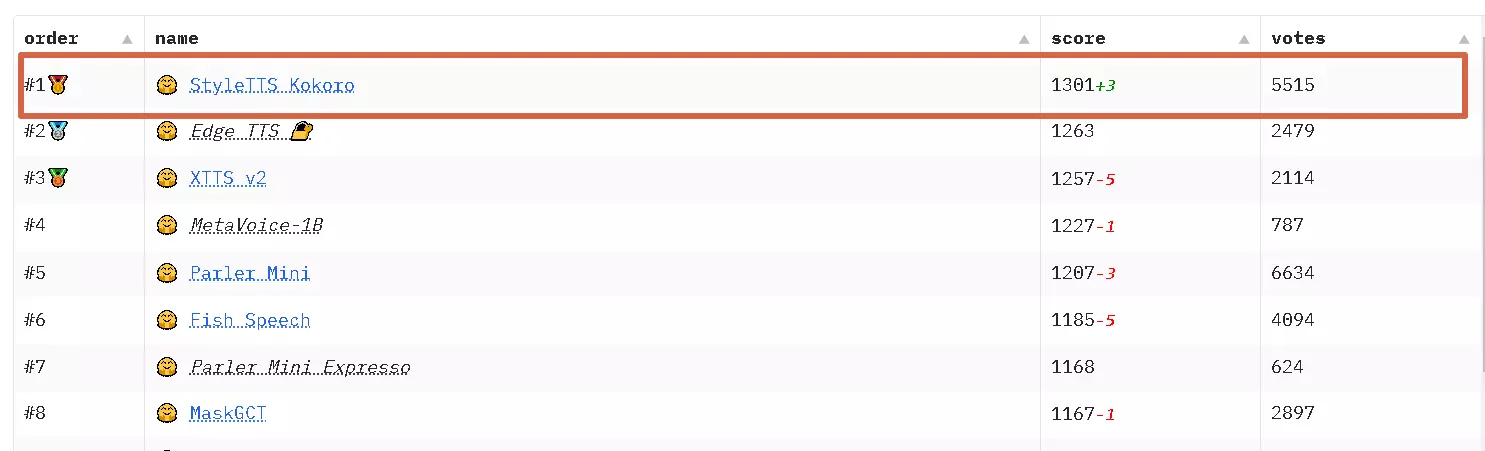
Kokoro TTS 全面解析:輕量級開源語音新星,現已支援中文! 深入了解 Kokoro TTS,這款僅有 8200 萬參數卻表現驚人的文字轉語音模型。本文將帶您一探其核心優勢、技術細...

Google突破性發布Veo 2與Imagen 3:AI影像生成的新紀元 文章摘要 Google DeepMind最新發布的Veo 2視頻生成模型和Imagen 3圖像生成模型,將AI創作推向...
GitHub Copilot 大升級:Agent 模式與 MCP 全面登陸 VS Code,程式碼編寫體驗再進化! VS Code 使用者注意!GitHub Copilot 迎來重大更新...
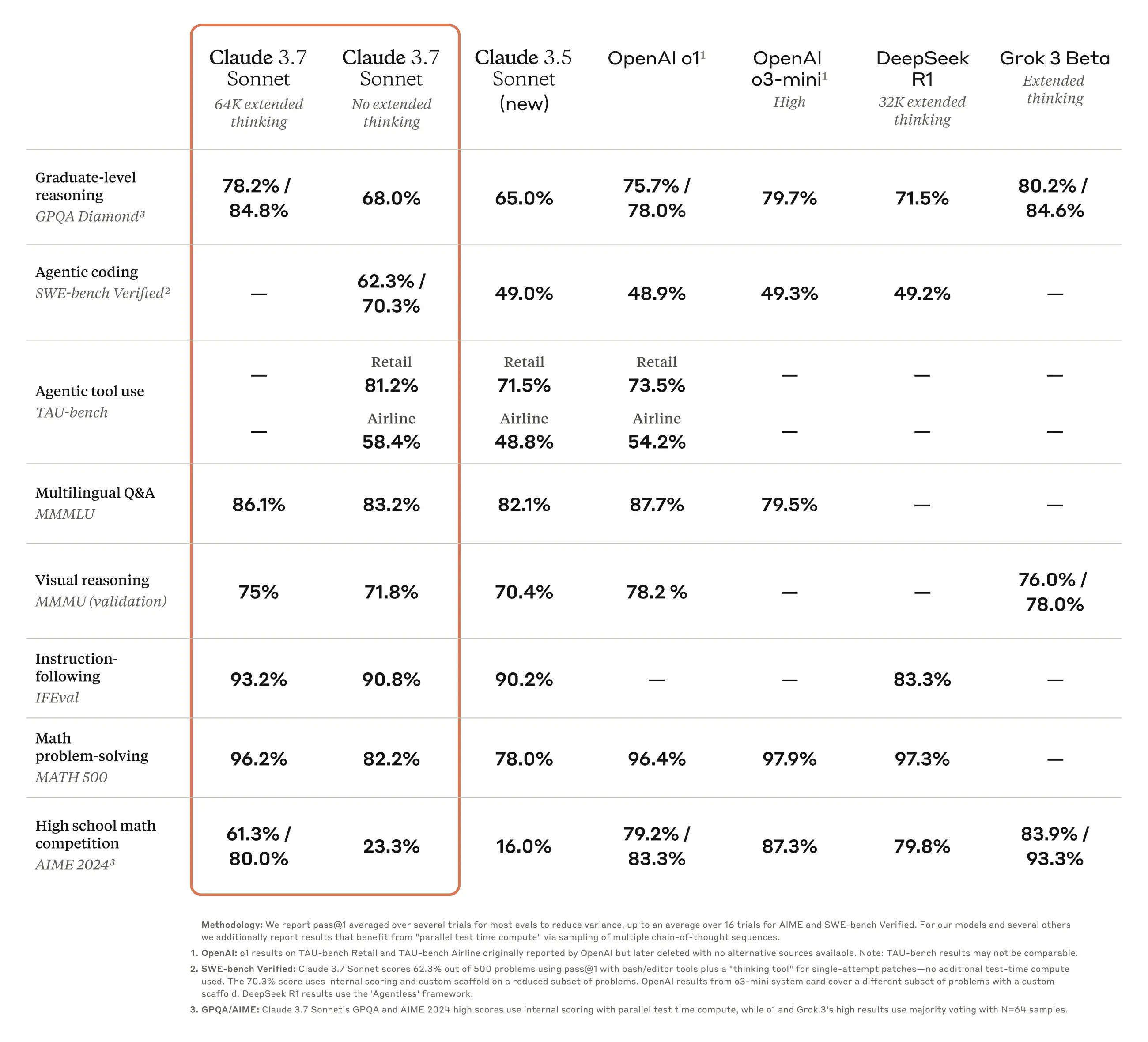
Claude 3.7 Sonnet:前沿推理與實用性的完美結合 全新升級的 Claude 3.7 Sonnet Anthropic 最新發布的 Claude 3.7 Sonnet,標誌著 A...