TANGOFLUX: Breakthrough AI Text-to-Audio Technology Generates 30-Second High-Quality Audio in 3.7 Seconds
Summary
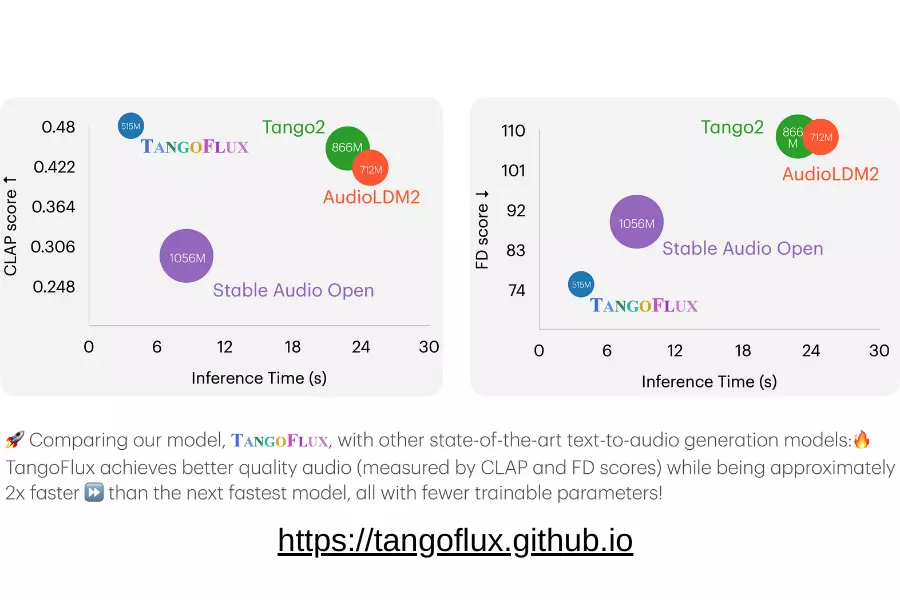
A breakthrough in artificial intelligence introduces TANGOFLUX, a new text-to-audio model with 515 million parameters. It can generate 30 seconds of high-quality audio in just 3.7 seconds, revolutionizing AI audio generation for film, gaming, and more.
Technical Breakthroughs
Core Features
- 515 million parameter model
- Runs efficiently on a single A40 GPU
- Supports 44.1kHz high-quality audio output
- Open-source code and model
Audio Generation Capabilities
TANGOFLUX excels at generating various sounds:
- Natural sounds (e.g., bird calls)
- Human-made sounds (e.g., whistles)
- Special effects (e.g., explosions)
- Music generation (under development)
Innovation: CLAP-Ranked Preference Optimization
Technical Solution
TANGOFLUX’s CRPO framework solves the preference matching challenge that traditional text-to-audio models face, unlike Large Language Models (LLMs) which have verifiable reward mechanisms.
CRPO Framework Benefits
- Iterative generation and optimization of preference data
- Improved model alignment
- Superior audio preference data
- Supports continuous improvement
Real-World Applications
TANGOFLUX shows leading advantages in objective and subjective benchmarks:
- Clearer event sounds
- More accurate event sequence reproduction
- Higher overall audio quality
Use Cases
- Film sound effects
- Game audio design
- Multimedia content creation
- Virtual reality audio generation
Examples
Visit official project page for examples.
Sample prompts:
1. A melodic human whistle harmoniously intertwined with natural bird songs.
2. A basketball bouncing rhythmically on the court, shoes squeaking on the floor, and a referee's whistle cutting through the air.
3. Water drops echo clearly, a deep growl reverberates through the cave, and gentle metallic scraping suggests an unseen presence.
FAQ
Q: How does TANGOFLUX handle complex sound combinations?
A: Through the CRPO framework, the model accurately understands and generates multi-layered sound combinations.
Q: What are the hardware requirements?
A: One A40 GPU is sufficient for efficient operation.
Future Outlook
TANGOFLUX will impact:
- Film production efficiency
- Game development costs
- Creative industry possibilities
- AI audio technology advancement
Practical Recommendations
For developers interested in TANGOFLUX:
- Study CRPO framework principles
- Start with simple sound generation
- Participate in open-source community
- Monitor official updates
Additional Links