Kokoro TTS: A Small but Mighty Open-Source Text-to-Speech Model? Full Guide Here!
Description: In the world of AI speech synthesis, does size really matter? Discover Kokoro TTS—a lightweight yet remarkably capable model. This article dives deep into its advantages, technical details, how to get started quickly, and why this 82-million-parameter model stands out among the competition.
Straight to the Point: What’s the Deal with Kokoro TTS?
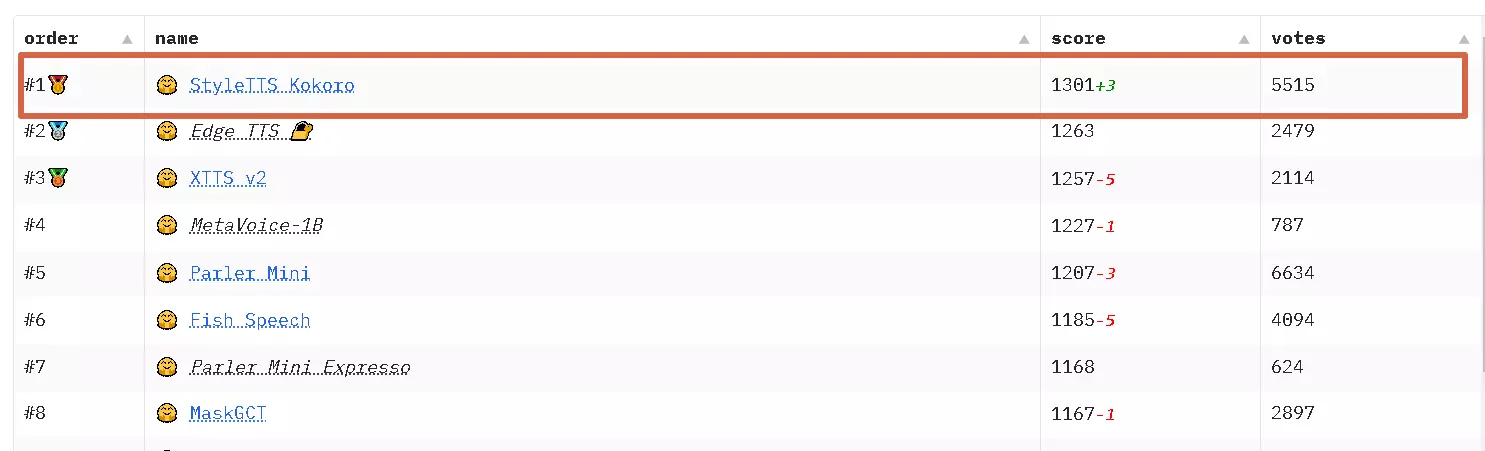
In the rapidly evolving field of AI-powered speech synthesis, some newcomers really catch your eye. Have you heard of Kokoro? This text-to-speech (TTS) model has made waves in the TTS Spaces Arena, proving that “small can beat big.” With just 82 million parameters, it has turned heads with its performance and innovative design.
What Makes Kokoro Stand Out?
Kokoro didn’t gain attention by chance. Here are some of the key highlights that make it special:
Surprisingly Impressive Results
Believe it or not, Kokoro v0.19 took first place in the single-speaker evaluation on TTS Spaces Arena! That’s a big deal considering it outperformed many models that are significantly larger in size. It shows that top-tier voice synthesis doesn’t have to rely on massive resources or overly complex models.
Diverse Voice Options to Suit Every Need
Kokoro offers more than just one voice. It includes 10 meticulously crafted voice packs, such as:
- Authentic American accents (e.g., Adam, Michael)
- Elegant British tones (e.g., Bella, Sarah)
- Other male and female voices with varying qualities and tones
Each voice pack is finely tuned to ensure clarity and natural delivery—perfect for audiobooks, video narration, or any TTS application.
Open Source for a Thriving Ecosystem
Kokoro is an open-source project under the Apache 2.0 license, which means:
- Commercial use is allowed—build products with it.
- Supports derivative work—modify and extend it freely.
- Community-driven development—everyone can contribute to improve it.
- Encourages innovation—open access promotes progress across the field.
Digging Deeper: The Technology Behind Kokoro
Let’s go beyond the hype and explore the tech that powers Kokoro.
Innovative Architecture
Kokoro follows a simple yet powerful design philosophy:
- Hybrid architecture based on StyleTTS 2 and ISTFTNet
- Uses a decoder-only structure—no traditional encoder involved
- No diffusion models, which cuts down on computational complexity
- Parameters are highly optimized for efficient voice generation
This design allows the model to stay lightweight while still producing high-quality speech.
Unique Training Data Sources
Kokoro’s training process also stands out:
- Trained on less than 100 hours of curated audio—a tiny dataset compared to others that use thousands of hours.
- All data was carefully selected to ensure legal licensing.
- Includes public domain audio and synthetic data from commercial TTS systems.
- This strategy ensures both quality and legal safety.
Impressive Cost Efficiency
Developing Kokoro was surprisingly cost-effective:
- Training was done on Vast.ai using an A100 80GB GPU.
- Reportedly, training costs were under $1 per hour.
- That’s a huge cost savings compared to traditional cloud services.
Want to Try It? Kokoro 1.0 User Guide
Feeling curious about Kokoro? Here’s how to get started:
- Try It Online:
- The fastest way is through its Hugging Face Spaces demo page.
- URL: hf.co/spaces/hexgrad/Kokoro-TTS
- Just type in text and instantly hear the generated speech—super convenient!
- Run It Locally:
- An example notebook is available on Google Colab to help you deploy it in your environment.
- Supports ONNX format, making cross-platform deployment easier.
- Full documentation and usage instructions are provided in the project.
Note: Kokoro 1.0 is a major milestone that integrates previous optimizations and may include new voice packs or performance upgrades. While the core architecture and strengths remain, version 1.0 is typically more stable and production-ready—highly recommended.
Honest Talk: Kokoro’s Current Limitations & Future Outlook
No technology is flawless, and Kokoro is no exception. Here are some areas with room for improvement:
- Voice Cloning
- Due to the limited training dataset, Kokoro does not currently support voice cloning.
- However, with more data in the future, this feature may become possible.
- Dependence on External G2P Tools
- Use Case Limitations
- Kokoro performs well for long-form content like article narration.
- But for dynamic, conversational use cases with rapid tone shifts, there’s room for improvement.
Need Help or Want to Join the Discussion?
If you run into issues or want to connect with other developers, check out these channels:
Final Thoughts: Kokoro’s Got Serious Potential
To sum it up, Kokoro TTS proves that in the world of text-to-speech technology, smart design often beats sheer model size. Its lightweight, efficient, and open-source nature makes it a project full of potential. With continued innovation and community support, Kokoro is poised to bring even more exciting developments to the table. Pretty cool, right?