DMflow.chat
廣告
一站整合多平台聊天,體驗真人與 AI 自由切換的新境界!支援 Facebook、Instagram、Telegram、LINE 及網站,結合歷史記錄、推播通知、行銷活動及客服轉接,全面提升效率與互動。
探索 OpenAI 最新的「強化學習微調 (Reinforcement Fine-Tuning, RFT)」技術,學習如何透過自訂模型優化 AI 的推理能力,應用於法律、醫學、金融等專業領域,並了解其對基因疾病研究的深遠影響。

Mark,OpenAI 的研究負責人,宣佈了「o1 系列模型」的正式上線,以及其未來將支援 API 的消息。重點提到了一項突破性的功能:支援模型自訂及「強化學習微調 (RFT)」。這項技術能幫助開發者和研究者創建專業化模型,適應於特定領域需求,如法律、醫學、工程等。
強化學習微調是一種新型模型優化技術,通過結合強化學習來提升 AI 的推理能力,適用於需要深度專業知識的場景。
相關案例:與 Thomson Reuters 合作,使用「o1 mini」模型開發法律助理 AI。
Julie W. 針對兩種方法的差異進行了解釋:
OpenAI 提供的自訂平台使用戶能夠輕鬆地微調模型。
研究重點
罕見基因疾病雖然個別罕見,但累計影響超過 3 億人,患者通常需經歷漫長的診斷過程。
John Allard 演示了如何應用強化微調技術,並分享了以下關鍵步驟:
OpenAI 正擴展強化微調技術的應用範圍,邀請擁有專家團隊的組織參與 Alpha 計畫。
計畫於明年初正式推出強化微調功能,期待更多機構探索和應用該技術。
Justin Ree 強調了強化學習對生物學研究的深遠影響,建議將現有的生物信息工具與 AI 模型結合,進一步改善醫療成果。
OpenAI 對未來應用強化微調技術持樂觀態度,並歡迎更多組織加入探索行列。
(以上文章人名可能有誤)
一站整合多平台聊天,體驗真人與 AI 自由切換的新境界!支援 Facebook、Instagram、Telegram、LINE 及網站,結合歷史記錄、推播通知、行銷活動及客服轉接,全面提升效率與互動。
OpenAI 即將發布開源推理o3-mini模型? OpenAI 即將發布一款具備推理能力的開源模型,這是自 GPT-2 之後,公司再次推出的重要開源模型。這次發布吸引了全球開發者的關注...
ChatGPT 原生圖片生成功能開放免費用戶使用!AI 創作邁入新時代? AI 圖像生成功能悄然擴展,免費用戶也能玩! OpenAI 最近釋出的 ChatGPT 圖片生成功能,在社群媒體上掀...
馬斯克的 AI 大棋局:xAI 與 X 正式合併,估值飆升 800 億美元,劍指 AI 霸權? 科技巨頭馬斯克震撼宣布旗下 AI 新創 xAI 與社群平台 X 正式合併!全股票交易推升 ...
Vecto3D:將你的 SVG 轉換成 3D 模型的超簡單工具 Vecto3D 是一款簡單易用的線上工具,專門用來將簡單的 SVG(主要是標誌)轉換為 3D 模型。你可以在 Vecto3...
開源 AI 音樂革命!YuE 模型正式發布,生成專業級人聲與伴奏 YuE:AI 音樂創作新時代的來臨 由 香港科技大學 與 DeepSeek 共同研發的 開源音樂生成模型 YuE 正式發布,...
Manus 正式推出付費方案:Starter 套餐每月 $39 美元 Manus 進軍付費市場,從免費試用轉向商業模式 在 AI 服務競爭日益激烈的市場中,Manus 正式宣布推出其首個付費...

OpenAI發布「Swarm」框架:AI多代理協作系統引發自動化新思考,或將重塑企業運營模式 📝 文章摘要 OpenAI最新推出的實驗性框架「Swarm」,為AI領域帶來重大突破。這個創新框架...

台積電重磅財報:AI晶片需求強勁,2024年後持續成長,引爆半導體股漲勢 📝 文章摘要 台積電(TSMC)第三季財報亮眼,受益於人工智慧(AI)晶片需求強勁,不僅超越華爾街預期,更上調全年營收...
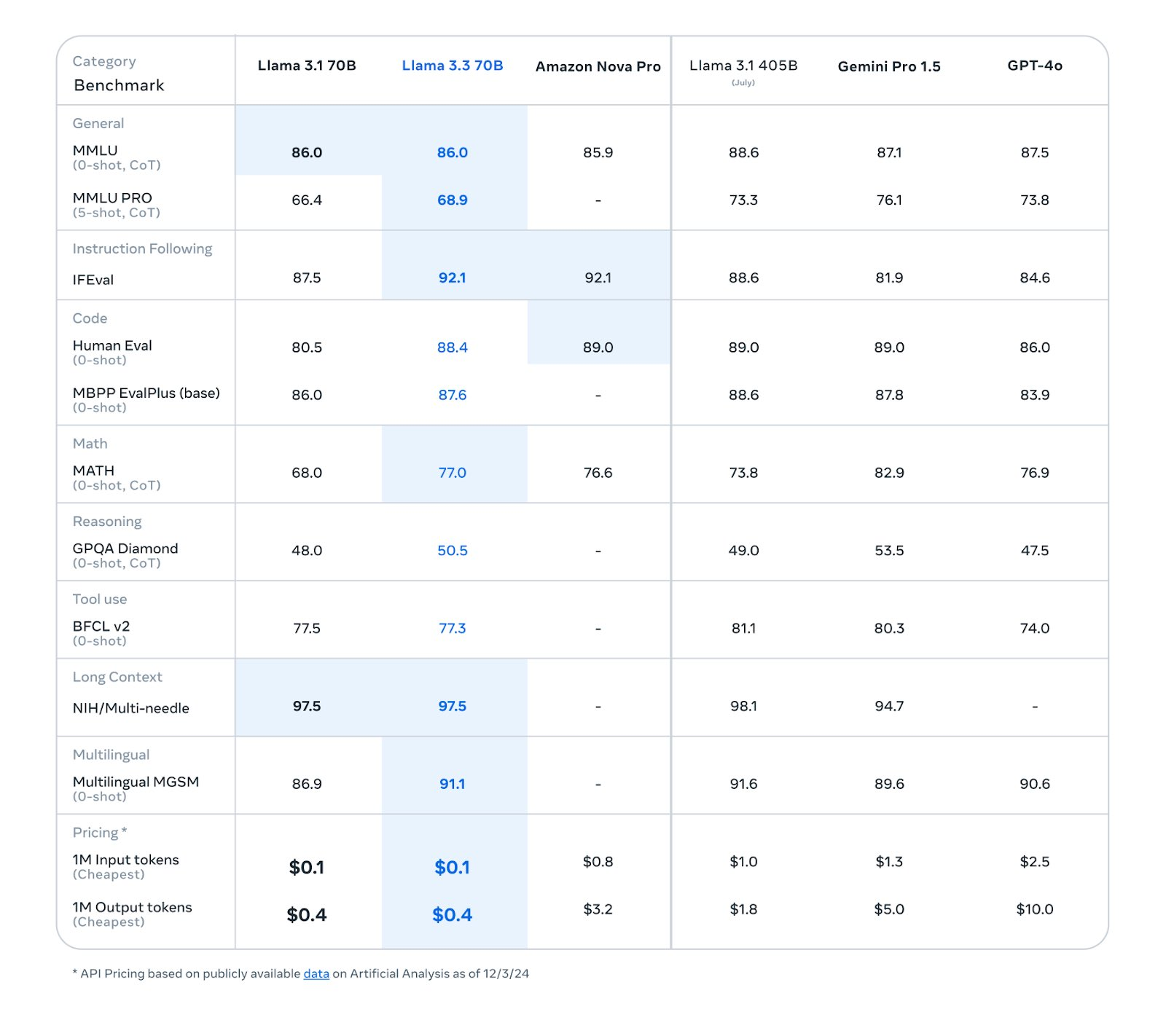
Meta 推出開源 Llama 3.3 70B,將強大的模型縮小為更小的尺寸 簡介 Meta 最新推出的 Llama 3.3 70B 模型,不僅以創新技術挑戰傳統規模極限,還以不足 Llama...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.