OpenAI Day12: AI模型重大突破:o3系列展現超越人類的推理能力
文章摘要
在人工智慧發展歷程中,迎來一個重要的里程碑:全新的o3系列模型於數學運算、程式編寫等領域展現前所未有的卓越效能,更在部分測試中締造超越人類的表現,寫下歷史新頁。本文將深入剖析o3系列的突破性進展,並闡述其對人工智慧發展的深遠影響。

重大發布活動回顧
在為期12天的盛大發布活動中,OpenAI不僅推出了首個推理模型o1,更預告了極具潛力的o3和o3 mini即將問世。這次發布獲得空前關注,標誌著AI技術發展的重要轉折點。
什麼是o3
o3是OpenAI最新的前沿模型,旨在顯著提升各種覆雜任務中的推理能力。它與其較小版本o3 mini一同發布,重點解決編碼、數學和通用智能方面的難題。o3的突出特點是它側重於更具挑戰性的基準測試,這些測試以以往模型難以企及的方式檢驗模型的推理能力。OpenAI強調了o3相對於o1的改進,將其定位為更強大的覆雜問題解決系統。
o3模型的突破性成就
o3模型在多個關鍵領域取得了顯著突破,尤其是在編程和數學領域表現卓越:
1. 編程能力的質變:
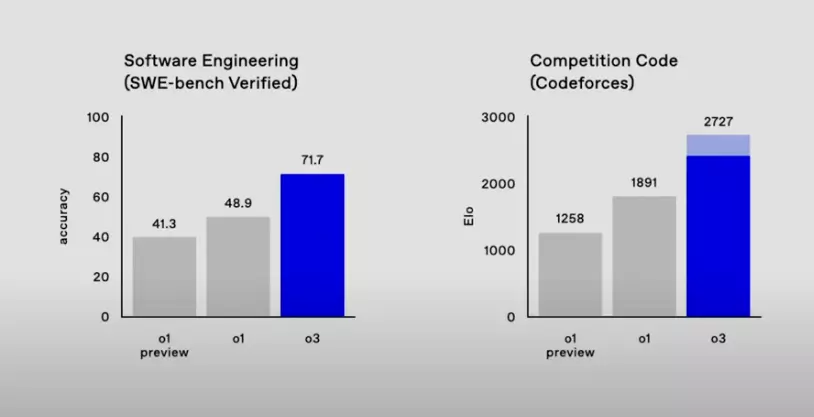
- SWE-bench Verified測試: o3的準確率達到71.7%,遠超o1的48.9%,提升幅度超過20個百分點,這表明o3在理解和生成代碼方面的能力實現了質的飛躍。這項測試評估模型在實際軟件工程任務中的表現,o3的優異成績意味著它在實際應用中擁有更大的潛力。這項測試模擬了真實的軟件工程場景,考察模型理解和修改代碼的能力,71.7%的準確率證明o3在處理實際編程任務時更加可靠。
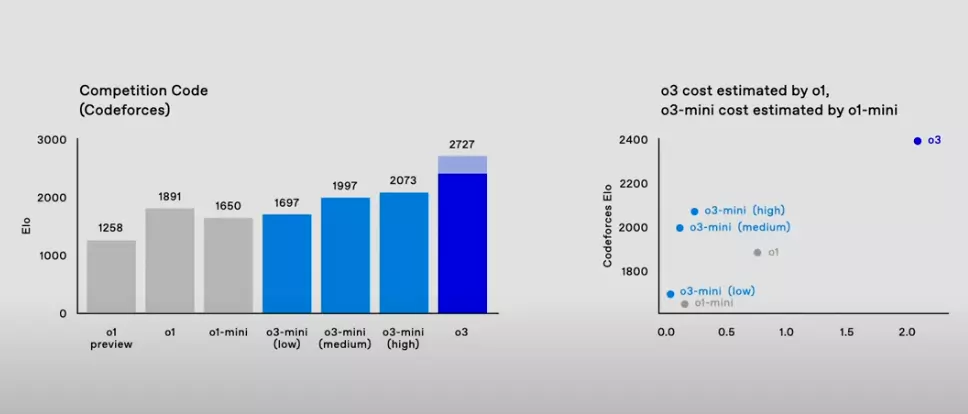
- Codeforces平台: o3在Codeforces平台上取得了2727的ELO分數,而o1為1891分,提升顯著。Codeforces是一個面向競技編程的平台,ELO分數用於衡量選手(或模型)的編程能力。o3的高分表明其在算法設計、代碼優化和問題解決方面達到了極高的水平,甚至可以與頂尖的人類程序員相媲美。有資料顯示,Codeforces上2400分以上就已經超越了99%的人類工程師,o3的2727分更是接近世界頂尖水平,這代表著它在算法競賽中已經具備了極強的競爭力。
2. 數學運算能力的躍進:
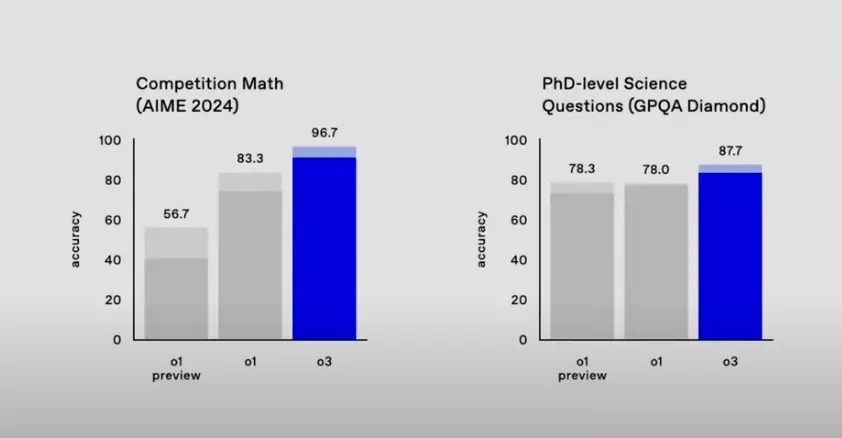
- AIME(美國數學邀請賽): o3在AIME測試中取得了96.7%的優異成績,而o1為83.3%。AIME是一項高難度的數學競賽,面向在美國數學奧林匹克競賽(USAMO)中表現優異的高中生。o3的高分表明其在解決覆雜數學問題方面具有卓越的能力。只錯一道題,更凸顯了其強大的數學推理能力。AIME考察的是高中階段高難度的數學問題,o3能取得如此高的分數,證明其在數學理解和解題技巧上都非常出色。
- GPQA Diamond測試: o3在該測試中得分87.7%,比o1高出10個百分點。GPQA Diamond是一個研究生水平的生物、物理和化學問題集,旨在評估模型在科學領域的知識和推理能力。o3的優異表現表明其在理解和應用科學知識方面取得了顯著進展,接近甚至超越了人類專家的水平。這項測試的難度很高,涵蓋了多個學科的專業知識,o3的高分體現了其在科學領域的廣泛知識和強大的推理能力。
- EpochAI Frontier Math測試: 這是另一個重要的數學基準測試,o3在這個測試中解決了25.2%的問題,而其他所有模型的成績都低於2%。這表明o3在處理極其覆雜和抽象的數學問題方面具有獨特的優勢,這些問題甚至需要頂尖的數學家花費數小時甚至數天才能解決。這項測試旨在考察模型處理前沿數學問題的能力,o3的突出表現表明其在解決高度覆雜和抽象的數學難題方面擁有巨大的潛力。
圖片擷取: https://www.youtube.com/live/SKBG1sqdyIU
從以上比較可以看出,o3相較於o1在編碼展現了顯著的進步。
- 程式設計: o3在SWE-bench和Codeforces上的大幅提升,顯示其在實際程式設計任務和演算法競賽中都更具優勢。
o1與o3比較
o3相較於o1在各個方面都展現了顯著的提升,尤其在程式編寫和數學運算方面取得了突破性的進展。這些進展不僅代表了AI技術的巨大飛躍,也預示著AI在解決複雜問題方面擁有更廣闊的應用前景。下表總結了兩者的主要差異:
| 特性 | o1 | o3 |
|---|---|---|
| 主要目標 | 展現通用推理能力 | 進一步強化推理能力,尤其在程式編寫、數學和通用智能方面 |
| SWE-bench準確率 | 48.9% | 71.7% |
| Codeforces ELO分數 | 1891 | 2727 |
| 開放使用 | 已發布 | 目前進行安全測試中,尚未全面開放使用 |
圖片擷取: https://www.youtube.com/live/SKBG1sqdyIU
從以上比較可以看出,o3相較於o1在數學和科學領域都展現了顯著的進步。
- 數學: o3在AIME中接近滿分的表現,證明其在解決複雜數學問題方面擁有卓越的能力。
- 科學: o3在GPQA Diamond測試中的提升,顯示其在理解和應用科學知識方面取得了顯著進展。
| 領域 | 評估標準 | o1 | o3 | 提升幅度 |
|---|---|---|---|---|
| 數學 | AIME準確率 | 83.3% | 96.7% | 13.4% |
| 科學 | GPQA Diamond準確率 | ~78% | 87.7% | ~10% |
EpochAI Frontier Math:o3在研究級數學問題上的突破
EpochAI Frontier Math是一個專門設計用來評估AI模型在極其複雜和抽象的數學問題上表現的基準測試。這些問題的難度非常高,甚至需要頂尖的數學家花費數小時甚至數天才能解決。因此,在這個測試中取得任何顯著的成果都代表著AI在數學推理領域的重大突破。
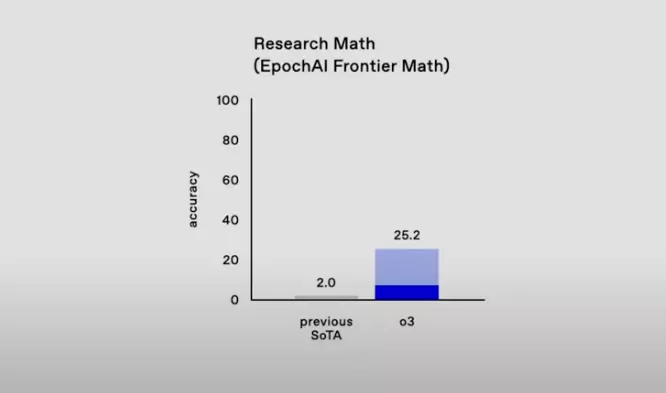
- 先前技術水準(previous SOTA): 準確率僅為2.0%。這意味著之前的最佳模型在這個測試中幾乎無法解決任何問題。
- o3: 準確率大幅提升至25.2%。相較於先前的技術水準,這是一個巨大的飛躍,顯示o3在處理極其複雜和抽象的數學問題方面具有獨特的優勢。
EpochAI Frontier Math的意義:
EpochAI Frontier Math測試的重要性在於它挑戰了AI模型處理超出傳統數學問題範圍的能力。這些問題通常需要:
- 高度抽象的思考: 問題的描述和解決方案可能涉及非常抽象的數學概念和結構。
- 多步驟的推理: 解決這些問題通常需要進行多個步驟的邏輯推理和數學運算。
- 創造性的問題解決: 有些問題可能沒有明確的解題方法,需要模型運用創造性的思維來尋找解決方案。
o3在EpochAI Frontier Math測試中取得的25.2%的準確率,不僅遠遠超過了先前的技術水準,更重要的是,它展現了AI在處理這類高難度數學問題方面的潛力。這項成果可能對未來的數學研究、科學發現以及其他需要複雜推理能力的領域產生深遠的影響。
EpochAI Frontier Math測試突顯了o3在研究級數學問題上的突破。相較於先前的技術水準,o3的表現有了顯著的提升,這證明了AI在處理極其複雜和抽象的數學問題方面取得了重大進展。這項成果不僅具有重要的學術意義,也為AI在科學和工程等領域的應用開闢了新的可能性。
在極其困難的數學問題上,o3遠遠超越了過去所有的AI模型,代表著AI在數學推理能力上的一個重大突破。
o3在ARC AGI上的突破
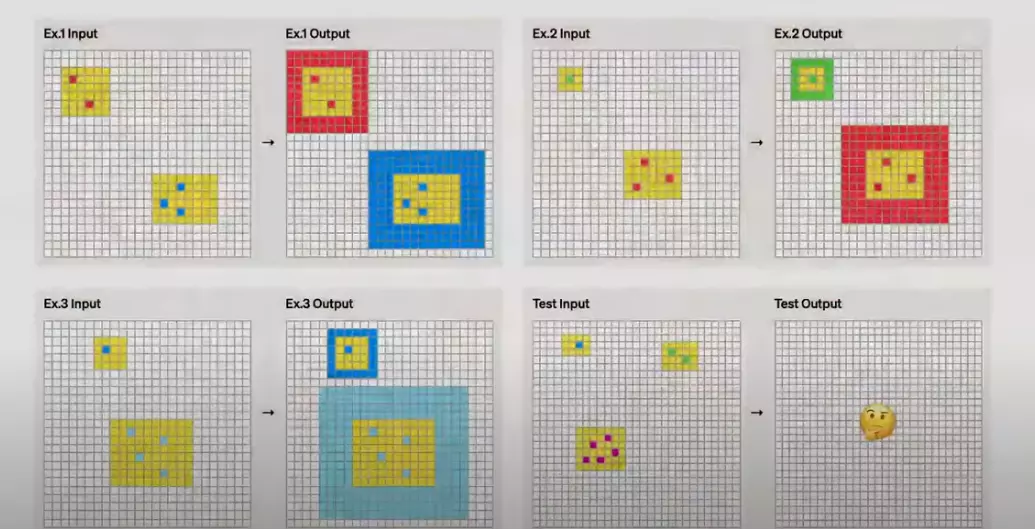
o3最令人矚目的成就之一,就是在ARC AGI基準測試中的優異表現。ARC AGI被廣泛譽為評估人工智慧通用智慧的黃金標準。
ARC(Abstraction and Reasoning Corpus,抽象與推理語料庫)由François Chollet於2019年開發,其重點在於評估人工智慧從極少量範例中學習和歸納新技能的能力。不同於經常測試預先訓練的知識或模式識別的傳統基準測試,ARC任務旨在挑戰模型即時推斷規則和轉換——這些任務對人類來說可以憑直覺解決,但人工智慧過去一直難以應付。
ARC AGI之所以特別困難,是因為每個任務都需要不同的推理技巧。模型不能依賴記憶的解決方案或模板;相反地,它們必須在每次測試中適應全新的挑戰。例如,一項任務可能涉及識別幾何變換中的模式,而另一項任務可能需要對數值序列進行推理。這種多樣性使ARC AGI成為衡量人工智慧是否能像人類一樣真正思考和學習的有效指標。
o3 mini:革新性的輕量級模型
降低AI應用門檻:經濟實惠的推理方案
- 經濟實惠的推理模型方案: o3 mini的主要目標是降低AI應用的門檻,讓更多機構和個人能夠使用先進的AI技術。
- 致力於普及AI技術: OpenAI希望透過o3 mini,讓中小型企業和個人開發者也能負擔得起高效能的AI解決方案。
- 成本效益的重大突破: o3 mini在成本效益上取得了重大突破,以更低的成本提供接近o3的效能。
效能評估:超越o1 mini,維持低成本
- 超越o1 mini: 在多項測試中,o3 mini的表現都超越了o1 mini,展現了顯著的進步。
- 維持較低的運營成本: 儘管效能有所提升,o3 mini仍然維持了較低的運營成本,使其更具吸引力。
- 中小型企業的可行方案: o3 mini為中小型企業提供了一個可行的AI解決方案,讓他們能夠在有限的預算下應用先進的AI技術。
創新基準測試的突破:展現卓越效能
- EpochAI前沿數學基準:
- 被譽為最具挑戰性的數學測試之一。
- o3模型取得了超過25%的準確率,遠遠超越先前的技術水準。
- 展現出解決複雜數學問題的強大能力。
- ARC AGI基準測試的里程碑:
- 在高算力設置下,o3模型達到了87.5%的得分。
- 首次超越人類85%的平均表現,這是一個重要的里程碑。
- 為AI的發展樹立了新的標準。
o3 mini的獨特之處:彈性思考時間
o3 mini的一個突出特點是其彈性思考時間,允許使用者根據任務的複雜程度調整模型的推理投入。
- 簡單問題: 針對較簡單的問題,使用者可以選擇低投入的推理模式,以最大化速度和效率。
- 複雜問題: 針對更具挑戰性的任務,使用者可以選擇高投入的推理模式,使模型的效能達到與o3相當的水平,但成本卻遠低於o3。
這種彈性對於在不同使用案例中工作的開發者和研究人員來說特別有吸引力,他們可以根據實際需求在效能和成本之間進行權衡。
安全性測試與發展方向:確保AI的可靠性
- 公眾安全測試計畫:
- 開放研究人員申請早期測試資格,以收集更多回饋並進行改進。
- 實施嚴格的安全測試程序,以確保模型的安全性和可靠性。
- 在提升模型能力的同時,將安全性放在首位。
- 深思熟慮的對齊技術:
- 採用創新的安全訓練方法,以提高模型識別安全與不安全提示的準確率。
- 為AI發展提供更可靠的安全保障,降低潛在風險。
常見問題解答
Q1:o3模型與o1模型相比有什麼主要改進?
A:o3模型在程式編寫、數學運算等領域都有顯著提升,例如在SWEET Bench測試中準確率提高20%,在Codeforces平台上的ELO分數提升超過800分。
Q2:o3 mini的主要優勢是什麼?
A:o3 mini主要優勢在於提供高性價比的AI解決方案,在保持較低運營成本的同時,性能仍優於o1 mini。
Q3:何時可以使用這些新模型?
A:預計o3 mini將於一月底推出,o3模型將隨後發布。目前已開放研究人員申請早期測試資格。
未來展望
隨著o3系列模型的推出,AI技術將進入一個嶄新階段。期待這些突破性進展能為各行各業帶來革新,推動人工智能技術的健康發展。
相關連結
- OpenAI Day11: ChatGPT桌面應用程式重大突破:新一代AI助手功能全面解析
- OpenAI Day10 ChatGPT全方位革新:電話、WhatsApp全面整合,AI溝通更簡單
- OpenAI Day9: 向全球開發者致敬:提升開發者體驗
- OpenAI Day8: ChatGPT 搜尋功能全新上線!全球用戶全面開放即時資訊查詢
- OpenAI Day7: 推出「Projects」功能整合對話與工作場景
- OpenAI Day6: 聊天機器人功能大升級:即時互動與節慶驚喜全新體驗
- OpenAI Day5: 蘋果裝置用戶的福音:ChatGPT 無縫整合 iOS、iPadOS 與 macOS,使用更便利!
- OpenAI Day4:深入了解 OpenAI 的 Canvas 功能與應用
- OpenAI Day3: 引領創新!Sora 產品發布會精彩回顧
- OpenAI Day2: 強化學習微調與模型自訂:未來 AI 的新趨勢
- OpenAI Day1: 推出 ChatGPT Pro,月費200美金,o1 正式版付費用戶已可使用