DMflow.chat
廣告
DMflow.chat:智慧整合,創新溝通!除了持久記憶與客製欄位外,更支持真人與 AI 的靈活轉換,無縫連接資料庫與表單,讓網頁互動更靈活高效。
Meta 最新發布的突破性人工智慧模型 Motivo,運用創新的無監督強化學習演算法,實現了虛擬人形代理的全身動作控制。這項技術無需額外訓練即可執行多樣化的任務,為元宇宙與虛擬實境體驗帶來革命性的進展。Motivo 不僅賦予虛擬化身更自然流暢的動作,更為沉浸式互動開創了嶄新可能。

圖片擷取自: https://metamotivo.metademolab.com/
Motivo 的核心優勢在於其強大的泛化能力和物理世界的逼真模擬,這使其在虛擬環境中能夠展現出自然且多樣化的行為。以下將詳細介紹其主要特點:
Motivo 最令人矚目的特點是其卓越的零樣本學習能力。這代表 Motivo 無需針對特定任務進行額外訓練,即可流暢地執行多種複雜的動作和行為,展現出高度的適應性。具體而言,Motivo 能夠:
Motivo 深度整合了物理引擎,確保所有動作都符合真實世界的物理規律,大幅提升了虛擬環境的真實感和沉浸感。這使得 Motivo 能夠:
Motivo 的卓越性能源於其創新的技術架構,核心是名為 FB-CPR 的演算法,以及精心設計的網路架構。以下將詳細說明:
Forward-Backward representations with Conditional Policy Regularization (FB-CPR) 演算法是 Motivo 的核心,它結合了無監督學習和模仿學習的優勢,賦予 Motivo 強大的泛化能力和逼真度。FB-CPR 的主要特點包括:
為了高效地執行 FB-CPR 演算法,Motivo 採用了精巧的網路架構,包含以下兩個關鍵組件:
為了驗證 Motivo 的性能和泛化能力,Motivo進行了嚴格的定量和定性評估,並與其他先進模型進行了比較。結果顯示,Motivo 在多個方面都展現出卓越的表現。
在多個標準測試基準上對 Motivo 進行了評估,結果顯示:
除了定量評估,Motivo還進行了人類評估,以更直觀地了解 Motivo 生成的動作是否自然、逼真。評估結果顯示:
Motivo 的突破性技術不僅在學術研究上具有重要意義,更在多個領域展現出廣闊的應用前景,有望為Motivo的生活帶來革命性的改變。
Motivo 的自然動作控制能力將大幅提升元宇宙和虛擬實境體驗的真實感和沉浸感:
Motivo 的技術也為機器人控制領域帶來了新的可能性:
Motivo 的技術也能應用於電腦動畫和遊戲產業:
為了幫助大家更深入地了解 Meta Motivo,我們整理了一些常見問題並提供解答:
A: Meta Motivo 與傳統動作控制模型最大的不同之處在於其強大的泛化能力。傳統模型通常需要針對特定的任務進行大量的訓練,才能達到較好的效果。而 Motivo 採用零樣本學習方法,這意味著它 無需針對新任務進行額外或重新訓練,即可在同一框架下處理多種不同類型的任務,例如動作追蹤、姿勢達成、獎勵目標優化等。這種無需額外訓練的特性,大幅降低了開發成本和時間,並提高了模型的靈活性和適用性。此外,Motivo 深度整合物理引擎,能產生更自然、更符合物理規律的動作,這也是傳統模型較難達成的。
A: 雖然 Motivo 在多個方面都表現出色,但目前仍存在一些局限性:
正積極研究並改進這些問題,以進一步提升 Motivo 的性能和穩定性。
A: Meta 已開放了 Motivo 的模型代碼和基準測試集,這代表著開發者現在就能開始探索並將其應用於各種實際產品和專案中。鼓勵開發者社群積極參與,共同推動這項技術的發展和應用。未來,也將持續更新和改進 Motivo,並探索更多可能的應用場景,例如元宇宙、虛擬實境、機器人控制、電腦動畫和遊戲等。
Meta Motivo 的問世,不僅代表了人工智慧控制領域的重大突破,更預示著一個嶄新紀元的來臨。其獨特的零樣本學習能力,賦予了虛擬化身和機器人前所未有的靈活性和適應性,為元宇宙、機器人技術、電腦動畫和遊戲等領域開啟了無限可能。
Motivo 的核心優勢在於:
這些優勢使得 Motivo 在多個領域展現出廣闊的應用前景,例如:
誠然,Motivo 目前仍存在一些局限性,例如在處理快速動作和地面動作時表現相對較差,以及偶爾可能出現不自然的抖動現象。然而,Meta 已開放了 Motivo 的模型代碼和基準測試集,這不僅展現了 Meta 對技術發展的開放態度,更意味著全球的開發者都能參與到 Motivo 的改進和應用中,共同推動這項技術的發展。
展望未來,隨著技術的不斷進步和社群的共同努力,Motivo 將克服現有的局限性,並在更多領域展現其強大的潛力,為Motivo的生活帶來更豐富、更便捷、更美好的體驗。Motivo 的開源也將加速相關領域的發展。
DMflow.chat:智慧整合,創新溝通!除了持久記憶與客製欄位外,更支持真人與 AI 的靈活轉換,無縫連接資料庫與表單,讓網頁互動更靈活高效。
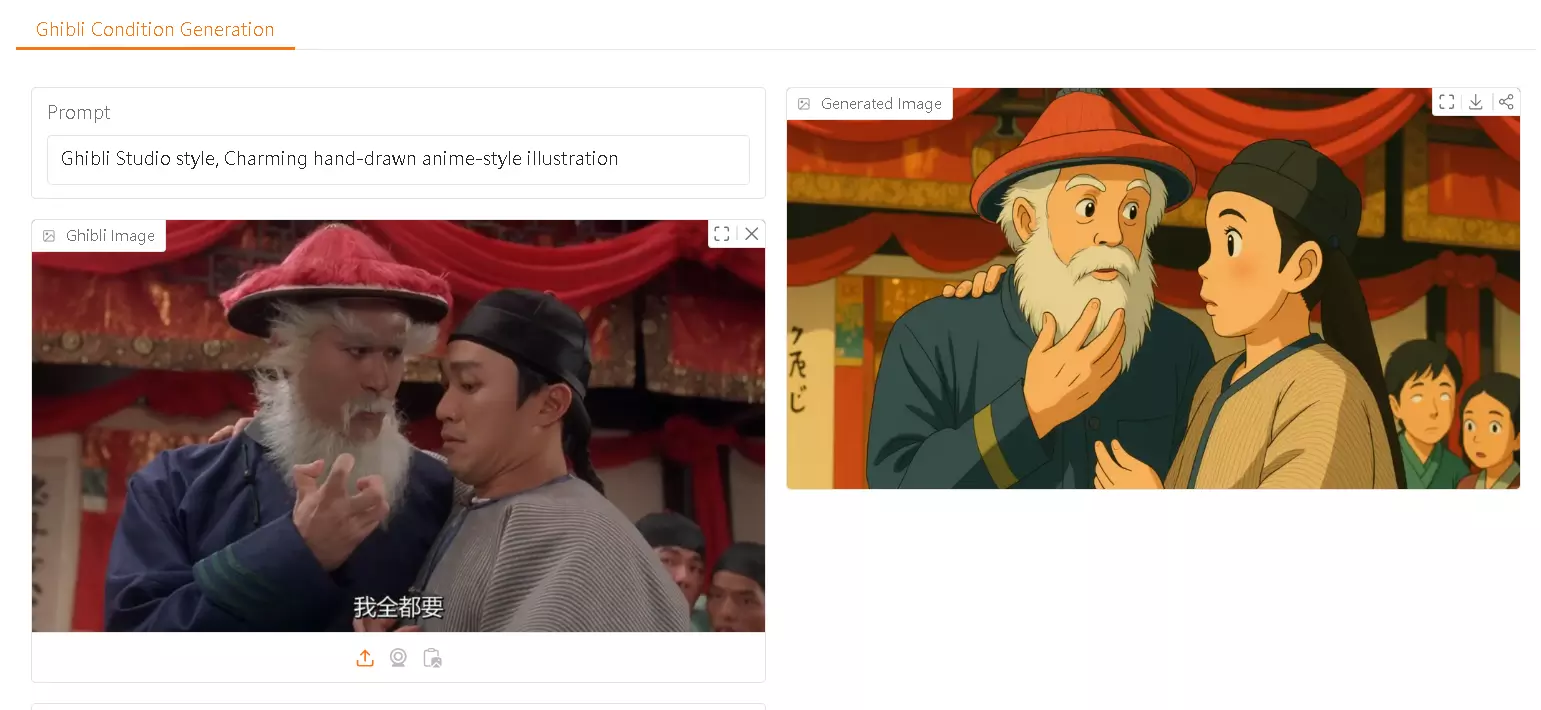
吉卜力風格免費玩!EasyControl_Ghibli 模型橫空出世,照片秒變動畫感 厭倦了 AI 繪圖工具的付費牆和限制嗎?最近 Hugging Face 上出現了一款名為 EasyC...

Reddit將推出AI驅動搜尋結果頁面:革新用戶體驗與內容探索 Reddit即將推出一項重大更新,為用戶帶來由人工智能(AI)生成的搜尋結果摘要。這項新功能旨在幫助用戶更深入地探索內容並發現新...
RF-DETR:開源且可商用的即時物件偵測模型 RF-DETR 是什麼? RF-DETR 是由 Roboflow 團隊開發並開源釋出的最新即時物件偵測(Real-time Object Det...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.