DMflow.chat
廣告
DMflow.chat:智能客服新世代!支援持久記憶、客製欄位,無需額外串聯即可輕鬆連接資料庫表單,整合多平台溝通,助您高效提升服務與行銷效率!
探索最新推出的開源OCR工具Llama-OCR,這款基於Llama 3.2 Vision的智慧影像辨識系統,不僅能夠精準辨識各類文件,更能直接輸出Markdown格式,為開發者和技術愛好者帶來全新的文件處理體驗。

傳統的OCR工具在處理複雜版面時常常力不從心。Llama-OCR採用先進的視覺AI技術,特別在以下方面展現優勢:
Llama-OCR運用視覺模型進行文件分析,具備以下特點:
npm install llama-ocrA:特別適合需要將圖片轉換為結構化文本的場景,如文件數位化、資料整理、文件管理系統等。
A:主要優勢在於直接輸出Markdown格式,以及對複雜版面的優異處理能力。
A:目前支援多種語言辨識,包括繁體中文在內的主要語言。
Llama-OCR團隊規劃了豐富的功能更新:
對於經常需要處理文件掃描的開發者來說,Llama-OCR提供了:
通過這些優勢,Llama-OCR正在重新定義OCR技術的應用範疇,為文件數位化處理帶來新的可能性。
可以前往來看影片範例
DMflow.chat:智能客服新世代!支援持久記憶、客製欄位,無需額外串聯即可輕鬆連接資料庫表單,整合多平台溝通,助您高效提升服務與行銷效率!

Runway 推出 Act-One:突破性 AI 角色動畫生成工具,輕鬆打造專業級動畫表演 文章摘要 Runway 最新發布的 Act-One 工具,只需基本的視頻和語音輸入,即可生成富有表現...

NotebookLM:Google最新AI筆記工具,讓你的研究效率倍增! 描述 想像擁有一位天才研究助理,能夠閱讀所有文件、完美總結,還能與你討論內容?Google的最新AI工具Noteboo...
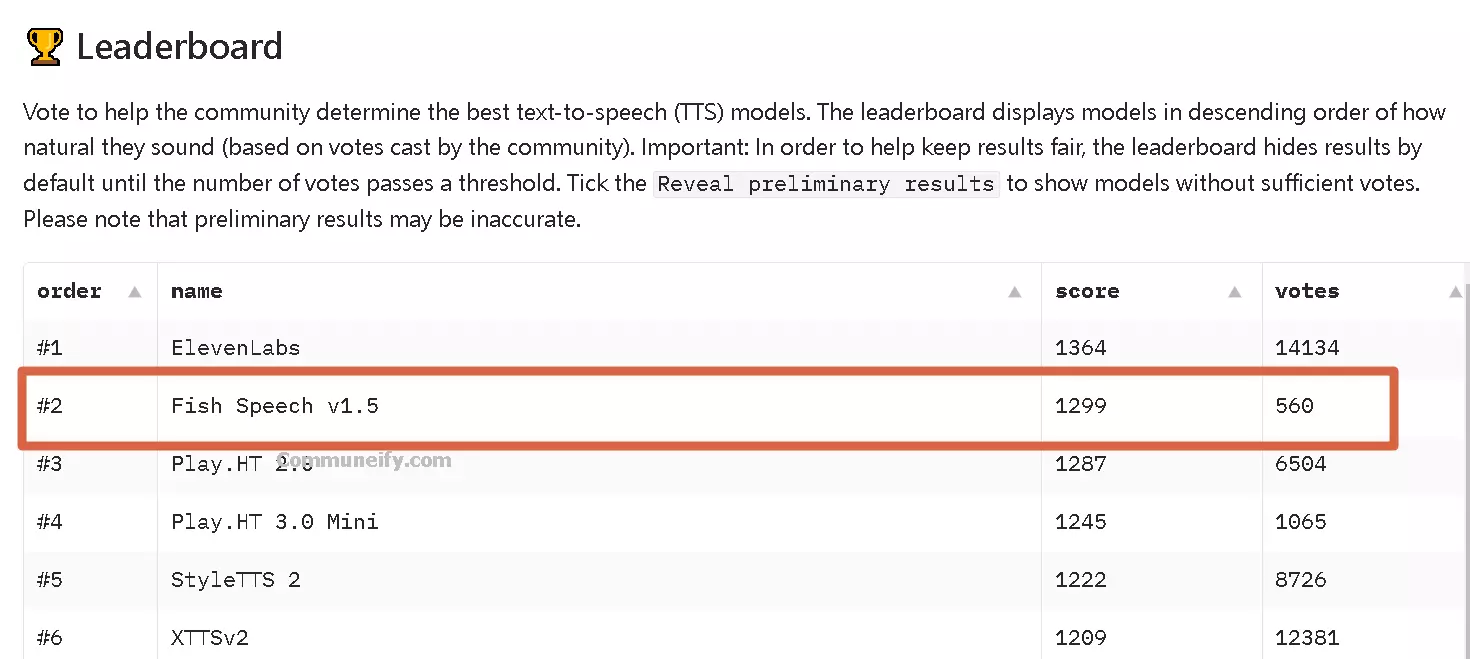
語音合成新時代:Fish Speech 1.5 推出五種新語言,實現即時無縫對話! 描述 Fish Audio 震撼發表全新語音合成模型 Fish Speech 1.5,不僅提升了準確度、穩定...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.