DMflow.chat
廣告
DMflow.chat:智慧客服新時代,輕鬆切換真人與 AI!持久記憶、客製欄位、即接資料庫表單,多平台溝通,讓服務與行銷更上一層樓。
近來,AI 技術的進步讓大型語言模型(LLM)變得愈發強大,然而,這些模型在處理資訊時產生「幻覺」(hallucination)——即生成錯誤或虛假的資訊——仍是一大挑戰。為了評估不同模型在資訊準確性上的表現,Vectara 推出了「幻覺排行榜」(Hallucination Leaderboard),並使用 Hughes 幻覺評估模型(HHEM-2.1)來測試 LLM 在摘要文件時產生錯誤資訊的頻率。
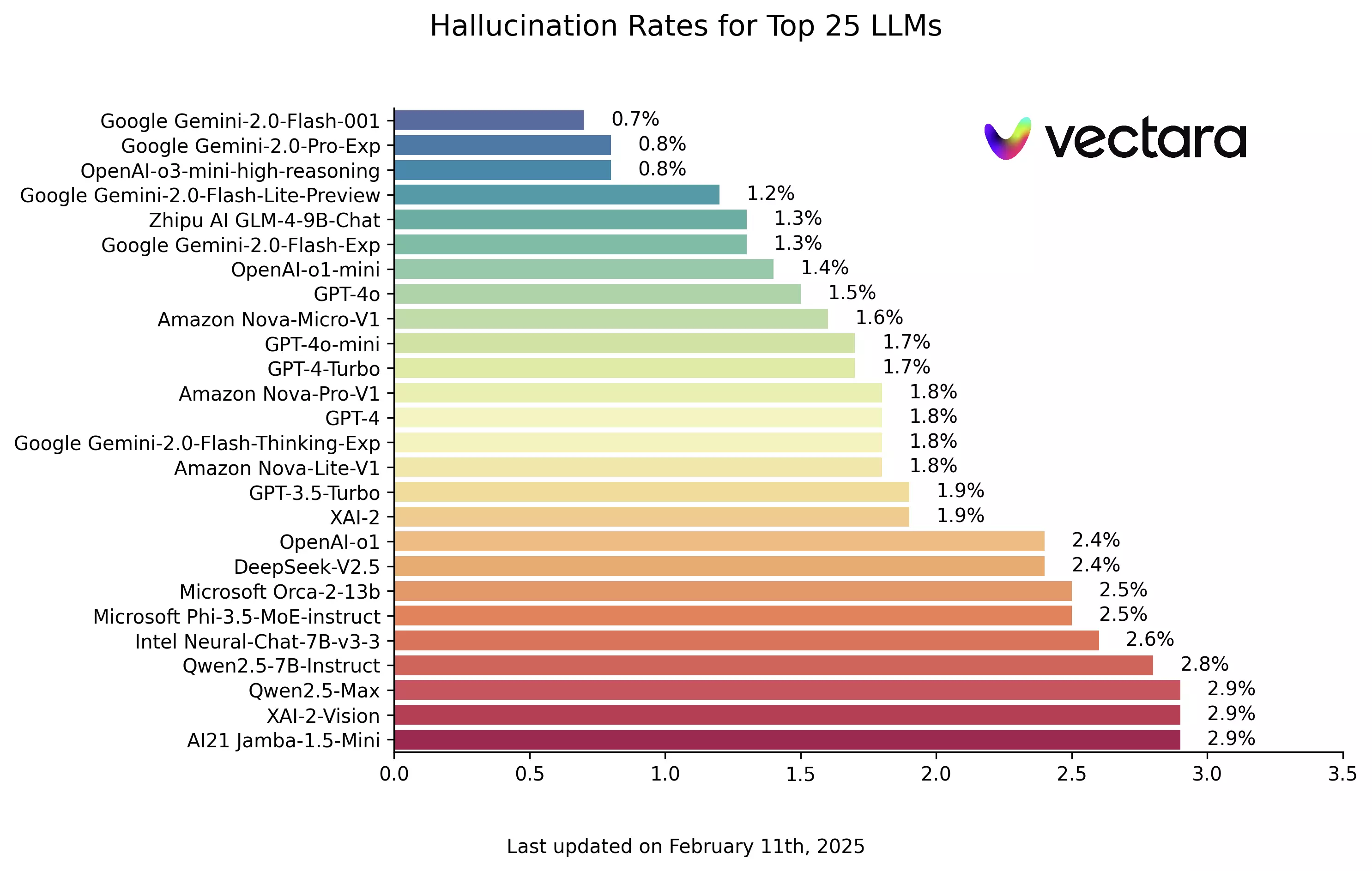
圖片來源: https://github.com/vectara/hallucination-leaderboard
最新排行榜顯示,Google 的 Gemini 2.0 Flash-001 模型表現卓越,幻覺率僅 0.7%,幾乎不會在文件處理過程中引入錯誤資訊。這意味著,它能夠以極高的準確度生成內容,為用戶提供可靠的摘要。
緊隨其後的則是 Gemini-2.0-Pro-Exp 與 OpenAI 的 o3-mini-high-reasoning,這兩款模型的幻覺率同為 0.8%。這一結果顯示,頂尖 LLM 已經在資訊準確性方面取得重大突破。
該報告不僅關注幻覺率,還評估了其他關鍵指標,包括:
以下是排行榜中的部分數據:
| 模型名稱 | 幻覺率 | 事實一致性率 | 回答率 | 平均摘要長度(字數) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7% | 99.3% | 100.0% | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8% | 99.2% | 99.7% | 61.5 |
| OpenAI o3-mini-high-reasoning | 0.8% | 99.2% | 100.0% | 79.5 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2% | 98.8% | 99.5% | 60.9 |
| Zhipu AI GLM-4-9B-Chat | 1.3% | 98.7% | 100.0% | 58.1 |
| OpenAI o1-mini | 1.4% | 98.6% | 100.0% | 78.3 |
| GPT-4o | 1.5% | 98.5% | 100.0% | 77.8 |
從這份數據可以看出,Google 的 Gemini 系列與 OpenAI 的新一代模型在減少幻覺方面均表現優異。其中,Gemini 2.0 Flash-001 無疑成為新一代 LLM 的領頭羊。
大型語言模型被廣泛應用於新聞摘要、醫學資訊、法律分析等領域,確保資訊的準確性至關重要。如果 LLM 無法提供可靠的資訊,可能會導致錯誤的決策或誤導公眾。因此,降低幻覺率是未來 AI 研究與應用的一大核心目標。
隨著 AI 技術的不斷進步,幻覺率的降低無疑是一個好消息。然而,LLM 仍然無法完全消除錯誤,開發者仍需持續改進模型的資訊過濾能力。同時,用戶也應該對 AI 生成的內容保持一定的批判性,透過多方驗證來確保資訊的真實性。
想要查看完整排行榜?請點擊這裡查看 Vectara 的官方數據。
這份最新的「幻覺排行榜」為研究人員、開發者以及普通用戶提供了有價值的參考,幫助大家了解當前 LLM 的表現,並為未來的 AI 發展方向提供指引。
DMflow.chat:智慧客服新時代,輕鬆切換真人與 AI!持久記憶、客製欄位、即接資料庫表單,多平台溝通,讓服務與行銷更上一層樓。
Gemini 2.5:Google 最強 AI 模型,邏輯推理與編碼能力再突破! 突破極限的 AI 智能——Gemini 2.5 誕生 Google 正式推出 Gemini 2.5,這是迄今...
Google AI Studio 現可透過 ai.dev 網域直接訪問! 簡單好記,Google AI Studio 進入全新時代 Google 今日正式宣布,開發者熟悉的 Google A...
Google AI Studio 影像生成功能升級:更低誤判率、更強大易用性 Google AI Studio 的重大更新:更準確、更高效的 AI 影像生成 Google 最近對其 AI 開...
Google Gemini 推出 Canvas 協作工作區與 Audio Overview 音訊摘要功能 讓 AI 更具互動性與創造力的新工具 Google 近日為旗下 AI 助手 Gemi...
Google Gemini 2.0 Flash 水印去除功能引發版權爭議 Google AI 新功能再掀版權風暴? 於先前發表的文章Google Gemini 2.0 Flash 解鎖原生圖...
Google Gemini 全新升級:更強的 AI 理解力、更貼心的個人化體驗 Gemini 2.0 Flash Thinking 登場:AI 理解力全面進化 Google 正式推出 G...

OpenAI 提供 GPT-4o mini 模型限時免費微調服務 OpenAI 現正為其 GPT-4o mini 模型提供限時免費微調服務。重要的是要注意,這項優惠僅持續到 2024 年 9 ...

NVIDIA RTX 50 系列顯示卡發布:AI 算力翻倍,開創遊戲與創作新紀元 重大突破:Blackwell 架構與 AI 技術 NVIDIA 最新發布的 GeForce RTX™ ...

BEN2:精準影像前景分割的 AI 解決方案 在影像處理領域,如何快速且準確地去除背景,一直是業界關注的重點。傳統方法依賴綠幕技術或手動摳圖,耗時且成本高昂。如今,BEN2 (Backg...
By continuing to use this website, you agree to the use of cookies according to our privacy policy.