被遺忘的名字:David Mayer 教授與 AI 模型中的身份迷霧
文章描述
在人工智慧快速發展的今天,一個學術名字如何在數位世界中被扭曲和遮蔽?David Mayer 教授的故事揭示了科技、隱私和身份認同之間錯綜複雜的關係,帶您深入探索 AI 對話模型中不為人知的命名之謎。
文章內容
AI 對話模型中的特殊名字處理機制
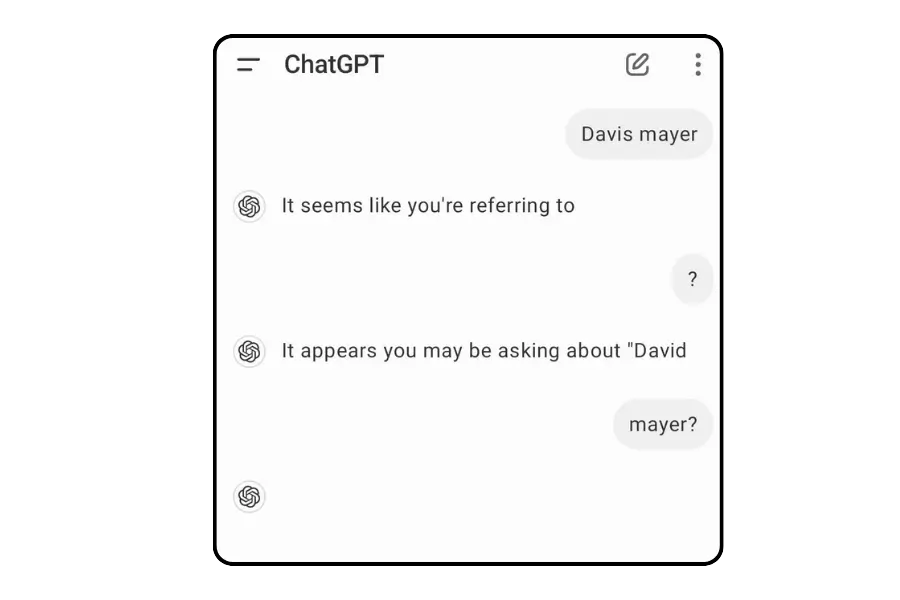
在人工智慧發展的浩瀚領域中,對話模型處理個人名字的方式常常令人費解。近期,一個關於特定名字在 ChatGPT 中被特殊處理的案例引起了廣泛關注。
異常名字清單中的關鍵人物
在這個獨特的名字清單中,我們發現了幾位值得注意的人物:
-
David Faber:長期在 CNBC 工作的資深記者。
-
Jonathan Turley:知名的法律評論員和福克斯新聞頻道評論家,在 2023 年底曾遭遇「惡意報警」(swatting)事件。
-
Jonathan Zittrain:法律專家,曾就「被遺忘的權利」(right to be forgotten)議題發表過許多見解。
-
Guido Scorza:意大利資料保護局的董事會成員。
一個特別的學術案例:David Mayer 教授
在這些名字中,David Mayer 的故事尤其引人注目。他是一位英裔美國學術界人士,主要研究領域為戲劇史和早期電影史。
學術生涯與身份困擾
Mayer 教授的學術生涯充滿挑戰。儘管在專業領域獲得尊重,但他卻長期面臨一個令人不安的問題:一位使用他名字的單臂恐怖分子。
這種身份混淆給 Mayer 教授帶來了嚴重的實際困擾。他甚至因為名字的關聯而無法自由旅行,不得不持續與這種情況抗爭。
AI 模型中的隱私與技術處理
複雜的後處理機制
對於 OpenAI 為何會對這些特定名字有特殊處理,目前仍然是一個謎。然而,業內人士推測,這很可能與模型的後處理規則有關。
這些規則可能包括:
- 針對特定名字的特殊響應邏輯
- 基於隱私考量的名字處理機制
- 防止敏感信息洩露的技術手段
技術實現的不確定性
正如文章作者所言,這更可能是技術實現中的一個小錯誤,而非有意為之。正如 Hanlon 剃刀原理所述:「不要將可以歸因於無知的事情歸咎於陰謀。」
對使用者的建議
在這個人工智慧高度發展的時代,我們應該:
- 保持批判性思維
- 不盲目相信 AI 提供的所有信息
- 在需要準確信息時,直接查閱可靠的原始來源
常見問題解答(FAQ)
Q1:為什麼 AI 模型會對某些名字有特殊處理?
A1:這可能涉及隱私保護、技術限制或特定的後處理規則,旨在保護個人信息和防止潛在的敏感信息洩露。
Q2:David Mayer 教授的故事告訴我們什麼?
A2:它凸顯了在數字時代,個人身份和隱私可能面臨的複雜挑戰,尤其是在人工智慧快速發展的背景下。
Q3:我們應該如何看待 AI 模型的這類行為?
A3:保持開放和批判的態度,認識到 AI 是一個不斷發展和改進的技術,存在各種局限性和不確定性。
結語
隨著人工智慧技術的不斷進步,我們將面臨越來越多關於隱私、技術倫理和個人身份保護的深刻問題。David Mayer 教授的故事提醒我們,在這個數位化的世界中,每一個名字背後都可能隱藏著複雜的人性故事。
備註
其實這個以前就知道了,例如:
若想完整使用可以透過api