
Meta has launched the Llama 3.1 series models, including the flagship model with 405B parameters, the first open-source model comparable to top-tier closed-source AI models. The new model extends context length, supports multiple languages, and offers more robust reasoning capabilities.
{: width=“100%” }
Image from Meet Llama 3.1{:target="_blank"}
Introduction to Llama 3.1
Llama 3.1 405B is the first publicly available model comparable to top AI models in general knowledge, controllability, mathematics, tool use, and multilingual translation. This version also includes upgraded 8B and 70B models, which are multilingual, with significantly longer 128K context lengths, state-of-the-art tool usage capabilities, and overall stronger reasoning capabilities.
This allows Meta’s latest models to support advanced use cases like long text summarization, multilingual conversational agents, and coding assistants. We’ve also modified the license to allow developers to use the output of Llama models to improve other models.
Model Architecture
Training the Llama 3.1 405B was a significant challenge, requiring training on over 15 trillion tokens. To achieve this scale of training in a reasonable timeframe and reach Meta’s results, we significantly optimized Meta’s full training stack and pushed Meta’s model training to over 16,000 H100 GPUs.
We adopted the standard decoder-only transformer model architecture, instead of an expert mixture model, to maximize training stability. We used an iterative post-training procedure, with each round involving supervised fine-tuning and direct preference optimization.
Instruction and Chat Fine-tuning
In Llama 3.1 405B, we focused on improving the model’s helpfulness, quality, and detailed instruction-following ability while ensuring high levels of safety. Meta’s biggest challenge was supporting more features, a 128K context window, and the increased model size.
In post-training, we generated the final chat model by aligning the pre-trained model over multiple rounds. Each round involved supervised fine-tuning (SFT), rejection sampling (RS), and direct preference optimization (DPO).
The Llama System
The Llama models have always aimed to work as part of an integrated system that can coordinate multiple components, including calling external tools. Meta’s vision is to go beyond base models to provide developers with broader system access, enabling them to flexibly design and create custom products that match their vision.
As part of Meta’s ongoing effort to responsibly develop AI beyond the model layer and help others do the same, we are releasing a complete reference system, including several example applications and new components like Llama Guard 3 (a multilingual safety model) and Prompt Guard (a prompt injection filter).
Openness Drives Innovation
Unlike closed-source models, Llama model weights are available for download. Developers can fully customize models according to their needs and applications, train on new datasets, and perform additional fine-tuning. This allows a broader developer community and the world to fully realize the power of generative AI.
Building with Llama 3.1 405B
Using a model of the 405B scale is challenging for ordinary developers. While it is a very powerful model, we recognize that it requires significant computational resources and expertise to use. Through community engagement, we understand that generative AI development is much more than just prompting models.
We want everyone to make the most of 405B, including real-time and batch inference, supervised fine-tuning, application-specific model evaluation, continuous pre-training, retrieval-augmented generation (RAG), function calling, and synthetic data generation.
Try the Llama 3.1 Model Series Now
We can’t wait to see what the community does with this work. With multilingual support and increased context length, there is a lot of potential to build useful new experiences. With the release of Llama Stack and new safety tools, we look forward to continuing to build responsibly with the open-source community.
Before releasing the model, we implemented several measures to identify, assess, and mitigate potential risks, including pre-deployment risk discovery exercises and safety fine-tuning through red teaming. For example, we conducted extensive red teaming with external and internal experts to stress test the models and identify unintended uses.
While this is Meta’s largest model to date, we believe there are many new areas to explore in the future, including scales more suitable for devices, additional modalities, and further investments in the agent platform layer. As always, we look forward to seeing all the amazing products and experiences the community will build with these models.
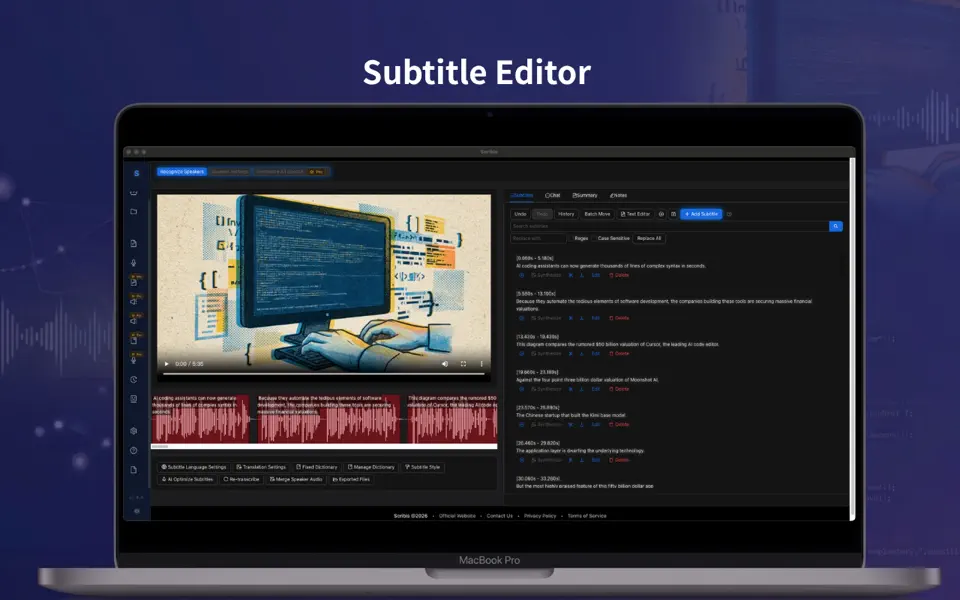
scribis.app
Scribis: Subtitle editing, audio transcription, and live transcription.
Learn More
DMflow.chat
Discover DMflow.chat and unlock the new era of AI-powered customer service.
Learn More
DMflow.chat
DMflow.chat: Your intelligent AI partner for exceptional customer engagement.
Learn More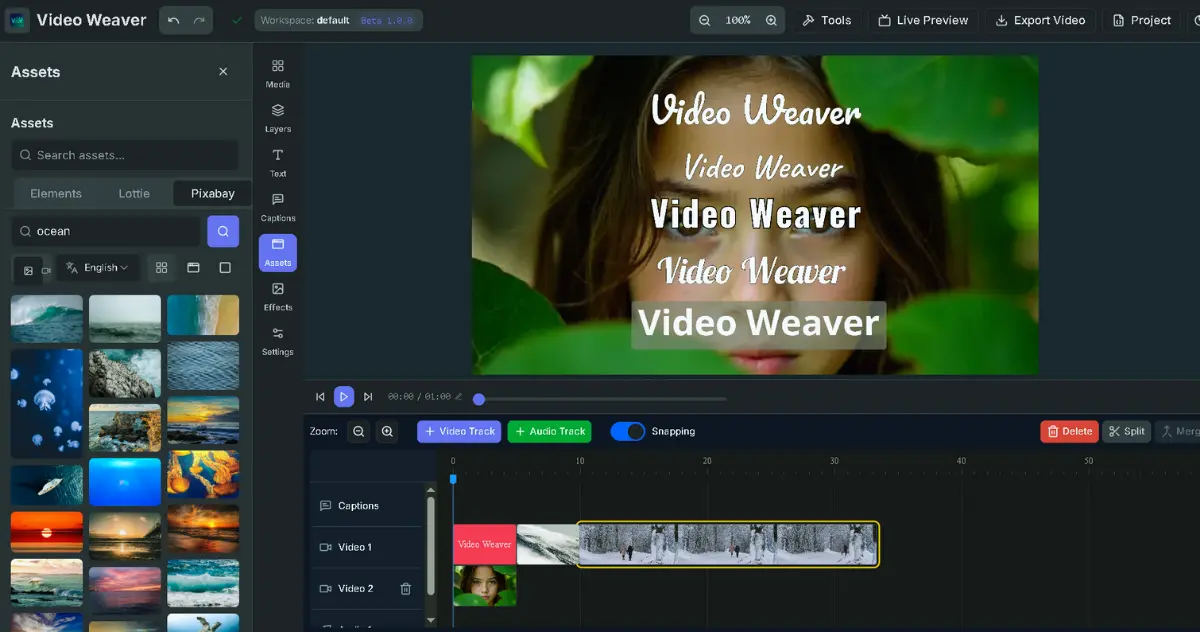
videoweaver.app
Video Weaver: Professional video editing directly in your browser. No downloads required.
Learn Morescribis.app
Scribis: Subtitle editing, audio transcription, and live transcription.
Learn MoreDMflow.chat
Discover DMflow.chat and unlock the new era of AI-powered customer service.
Learn MoreDMflow.chat
DMflow.chat: Your intelligent AI partner for exceptional customer engagement.
Learn Morevideoweaver.app
Video Weaver: Professional video editing directly in your browser. No downloads required.
Learn More