RAG即服务:释放企业生成式AI潜力
随着大型语言模型(LLMs)和生成式AI趋势的崛起,将生成式AI解决方案整合到企业中可以极大地提升工作效率。如果您是生成式AI的新手,大量的术语可能会让人望而生畏。本文将解释生成式AI的基本术语,并指导您如何通过RAG即服务为企业定制AI解决方案。
什么是检索增强生成(RAG)?
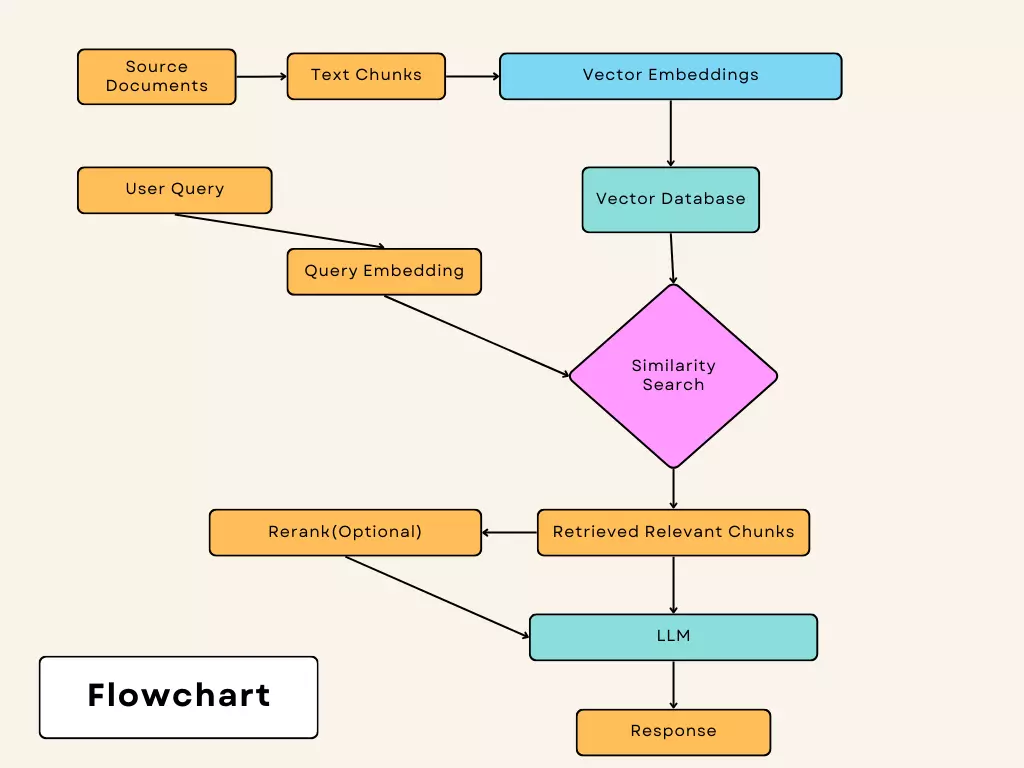
检索增强生成(RAG)是在企业工作流程中实现LLMs或生成式AI的关键概念。RAG利用预训练的Transformer模型,通过在查询过程中注入来自您特定知识库的相关数据来回答业务相关问题。这些数据是LLMs未经训练的,从而生成准确且相关的回应。
RAG不仅具有成本效益,而且高效,让生成式AI更易于接近。让我们来探索一些与RAG相关的关键术语。
RAG的关键术语
分块处理
LLMs资源密集,训练时使用可管理的数据长度,称为”上下文窗口”。上下文窗口根据所使用的LLM而异。为了解决其限制,提供的业务数据如文档或文本文献被分割成较小的块。这些块在查询检索过程中使用。
由于这些块是非结构化的,查询与知识库数据在语法上可能不同,因此使用语义搜索来检索这些块。
向量数据库
像Pinecone、Chromadb和FAISS这样的向量数据库存储业务数据的嵌入。嵌入将文本数据转换为数值形式,根据其意义存储在高维向量空间中,其中语义相似的数据彼此接近。
当用户查询时,查询的嵌入用于在向量数据库中查找语义相似的块。
RAG即服务(RaaS)流程
如果缺乏技术专长,为企业实施RAG可能会让人望而生畏。这就是RAG即服务(RaaS)发挥作用的地方。
常见问题解答
1. 什么是RAG即服务(RaaS)?
RAG即服务(RaaS)是一个全面的解决方案,处理您企业的整个检索增强生成过程。这包括数据分块、在向量数据库中存储嵌入,并管理语义搜索以检索查询的相关数据。
2. 分块处理在RAG过程中有何帮助?
分块处理将大型业务文档分割成适合LLM上下文窗口的较小块。这种分割允许LLM使用语义搜索更高效地处理和检索相关信息。
3. 什么是向量数据库,为什么它们重要?
向量数据库存储业务数据的数值表示(嵌入)。这些嵌入允许在查询时高效检索语义相似的数据,确保LLM提供准确且相关的回应。
4. 如何建立RAG